【PyTorch】Autogradで自動微分する方法について



1. Autogradとは?
Autogradは、PyTorchの主要な機能の一つで、自動微分を可能にします。自動微分とは、数式を手で微分することなく、計算グラフを通じて勾配(微分値)を自動的に計算する技術です。ニューラルネットワークのパラメータ(重み)を訓練する際に勾配降下法を使いますが、この勾配の計算を簡単にしてくれるのがAutogradです。
1.1. 計算グラフとは
Autogradが動作するための基盤となるのが計算グラフです。計算グラフは、数学的な計算をノードとエッジで表現するグラフ構造で、各ノードが演算を表し、エッジがデータの流れを示します。PyTorchは、この計算グラフを動的に構築し、後から微分の計算を追跡することで勾配を求めます。これを動的計算グラフと呼びます。
2. Autogradの使い方
Autogradは非常にシンプルなインターフェースを提供しています。PyTorchのテンソル(Tensor)にはrequires_gradという属性があり、これをTrueに設定することで、そのテンソルに対する操作が追跡され、勾配を計算できるようになります。
次に、簡単な例を見てみましょう。
import torch
# テンソルを定義し、勾配計算を有効にする
x = torch.tensor(5.0, requires_grad=True)
# 関数 y = x^4 を定義
y = x ** 4
# 勾配を計算
y.backward()
# xに対するyの勾配(dy/dx)を取得
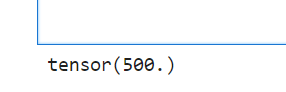
print(x.grad)
上記のコードでは、y = x^4 という式の勾配を求めています。y.backward()を呼び出すと、計算グラフを逆向きにたどって勾配が計算されます。
2.1. backwardと勾配計算の流れ
y.backward()を呼び出すと、Autogradは計算グラフを通じて逆伝播を行い、各テンソルの勾配を計算します。このプロセスは、ニューラルネットワークの学習におけるバックプロパゲーション(誤差逆伝播法)と同じです。
ここで重要なのは、requires_grad=Trueに設定されたテンソルだけが勾配を追跡し、それ以外のテンソルには勾配が計算されないという点です。これにより、不要な計算を避けて効率的に勾配を求めることができます。
2.2. 勾配の停止
転移学習など計算の一部で勾配を計算したくない場合もあります。その場合、torch.no_grad()コンテキストを使うと、勾配追跡を一時的に停止できます。これは推論時(モデルの訓練を行わないとき)に特に有用です。
import torch
x = torch.tensor(3.0, requires_grad=True)
with torch.no_grad():
y = x ** 4
# この場合、yは勾配を持たない
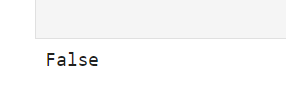
print(y.requires_grad) # 出力: False
with torch.no_grad():の内では、勾配が追跡されないです。
2.3. detachによる計算グラフからの分離
もう一つの方法として、.detach()メソッドを使って特定のテンソルを計算グラフから切り離すことができます。これにより、オリジナルのテンソルはそのまま勾配を持ちつつ、計算グラフから独立したコピーを生成できます。
x = torch.tensor(5.0, requires_grad=True)
y = x ** 3
z = y.detach() # 勾配の追跡から分離されたテンソル
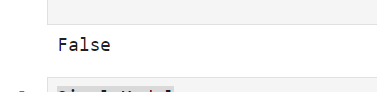
print(z.requires_grad) # 出力: False
.detach()を使うことで、テンソルの値だけを使い、勾配の計算を必要としない操作に利用することができます。
3. 実際の利用例
Autogradはニューラルネットワークの訓練に欠かせません。たとえば、損失関数を計算した後、その損失関数を.backward()で逆伝播することで、モデルのパラメータに対する勾配を求めます。この勾配を用いて、オプティマイザがパラメータを更新することで、モデルが学習します。
import torch
import torch.nn as nn
import torch.optim as optim
# シンプルな線形モデル
model = nn.Linear(1, 1)
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 入力とターゲットの定義
x = torch.tensor([[1.0], [2.0], [3.0]], requires_grad=True)
target = torch.tensor([[2.0], [4.0], [6.0]])
# 損失関数の定義
criterion = nn.MSELoss()
# 順伝播
output = model(x)
loss = criterion(output, target)
# 逆伝播
loss.backward()
# 勾配を使ってパラメータを更新
optimizer.step()
上記の例では、loss.backward()によって損失関数の勾配を計算し、optimizer.step()でパラメータの更新を行っています。パラメータの更新を5回行うと、モデルの出力は次のようになります。
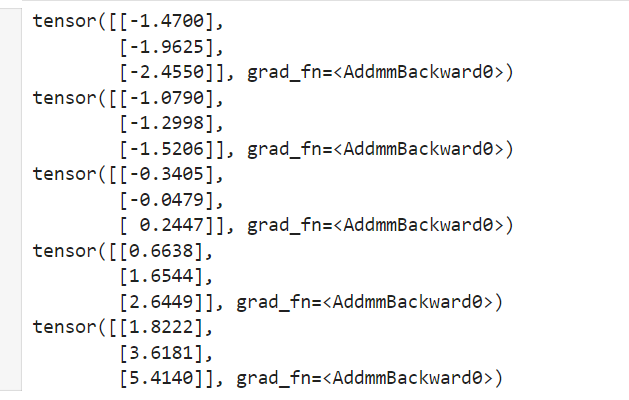 そして、最終的に、
そして、最終的に、

だんだんと、目標である[[2.0], [4.0], [6.0]]に近づいていることを確認できます。
4. まとめ
Autogradは、PyTorchにおける自動微分の仕組みを提供し、ニューラルネットワークの訓練を容易にします。計算グラフを使った自動微分、.backward()による逆伝播、勾配の停止と.detach()などの基本機能を理解することで、PyTorchを使ったモデルの開発がより効率的に行えるようになります。




