【ゆるーく入門】AWKの基本的な使い方とデータ集計について



- 1. AWKとは何か?
- 1.1. AWKの概要
- 1.2. 特徴
- 1.3. サンプル
- 1.3.1. logfile.txt
- 1.3.2. sample.txt
- 1.3.3. data.txt
- 1.3.4. csvのデータ
- 2. AWKの基本構文
- 2.1. AWKコマンドの基本形式
- 2.2. レコードとフィールド
- 2.3. パターンとアクションの構成
- 2.4. BEGINとENDセクションの役割
- 3. 基本的な使い方
- 3.1. テキストファイルのデータ処理
- 3.2. 特定の列の抽出
- 3.3. 条件に基づく行の抽出 (ifや/pattern/)
- 3.3.1. 例1: 数値条件
- 3.3.2. 例2: 正規表現
- 4. AWKの出力処理
- 4.1. 標準出力の基本
- 4.2. printとprintfの使い分け
- 4.3. カスタマイズされた出力フォーマット
- 5. 便利な組み込み関数
- 5.1. 数値演算関数
- 5.2. 文字列操作関数
- 5.3. 配列操作の基本
- 6. AWKスクリプトの作成と実行
- 6.1. スクリプトファイルの作成と実行
- 6.2. シェルスクリプトとの組み合わせ
- 7. AWK特有の記号
- 7.1. NR
- 7.2. NF
- 7.3. FNR
- 7.4. RS
- 7.5. FS
- 7.6. OFS
- 8. 条件分岐とループ
- 8.1. if-else文の使い方
- 8.2. forやwhileループによる繰り返し処理
- 9. CSVファイルの処理
- 9.1. 特定の列を抽出
- 9.2. 条件付きで行を抽出
- 9.3. 新しいCSVファイルの作成
- 10. ログファイルの解析
- 10.1. エラー行の抽出
- 10.2. 特定の時間帯のログを抽出
- 10.3. ログの集計
- 11. データの集計と統計処理
- 11.1. 合計と平均値の計算
- 11.2. 最大値と最小値の計算
- 11.3. ヒストグラムの作成
1. AWKとは何か?
1.1. AWKの概要
AWKは、主にテキスト処理を目的としたプログラミング言語およびツールです。名前の由来は、開発者であるAlfred Aho、Peter Weinberger、Brian Kernighanの頭文字に基づいています。UnixやLinux環境で使用されることが多く、データの抽出、加工、レポート生成に優れています。
1.2. 特徴
AWKの特徴は以下の通りです:
- テキストを行単位で処理し、特定の条件に一致する行に対して操作を実行できる。
- 組み込みのパターンマッチング機能を持ち、正規表現を活用できる。
- プログラムを書く手間が少なく、コマンドラインで簡単に処理を実行可能。
例えば、大量のログデータから特定の条件に一致する情報を抽出したり、CSVファイルを操作する際に便利です。
1.3. サンプル
本環境では、次のようなテキストをつかってawkの動作を見ていきます。
1.3.1. logfile.txt
2024-12-29 10:00:01 INFO User login successful: user_id=12345
2024-12-29 10:05:43 ERROR Unable to connect to database
2024-12-29 10:10:22 WARN Disk space low: remaining=5GB
2024-12-29 10:15:00 INFO Backup completed successfully
2024-12-29 10:20:11 ERROR Failed to process request: request_id=67890
2024-12-29 10:25:33 INFO User logout: user_id=123451.3.2. sample.txt
apple
banana
cherry
apple pie
pineapple
banana bread1.3.3. data.txt
A 10
B 20
C 30
D 401.3.4. csvのデータ
user_id,name,age,score
12345,John Doe,29,85.5
67890,Jane Smith,34,92.3
11223,Emily Davis,22,74.8
33445,Chris Wilson,40,88.1
55667,Sarah Lee,31,90.02. AWKの基本構文
2.1. AWKコマンドの基本形式
AWKの基本的なコマンド形式は以下の通りです:
awk 'パターン { アクション }' ファイル名- パターン: 処理する条件を指定します。条件を満たす行が対象となります。
- アクション: 条件に一致した行に対して実行する操作を指定します。例えば、出力、カラムの操作、数値の計算などです。
例:
awk '/ERROR/ { print $0 }' logfile.txtこのコマンドは、logfile.txt内で”error”を含む行をすべて表示します。

2.2. レコードとフィールド
awkでテキストを抽出するためには、レコードとフィールドを理解する必要があります。
- レコード: テキストデータを「行単位」で区切ったものがレコードです(デフォルトでは1行が1レコード)。
- フィールド: レコード内の「要素」で、デフォルトではスペースやタブで区切られた部分を指します。
たとえば、次のようなデータがあったとします。
John Smith 30 Engineer #レコード1
Jane Doe 25 Designer #レコード2
Alice Brown 22 Developer #レコード3- このファイルには3つのレコード(行)が含まれています。
- 各レコードには4つのフィールド(名前、名字、年齢、職業)があります。
| レコード番号 | フィールド番号 | 内容 |
|---|---|---|
| 1 | 1 | John |
| 1 | 2 | Smith |
| 1 | 3 | 30 |
| 1 | 4 | Engineer |
| 2 | 1 | Jane |
| 2 | 2 | Doe |
| 2 | 3 | 25 |
| 2 | 4 | Designer |
| 3 | 1 | Alice |
| 3 | 2 | Brown |
| 3 | 3 | 22 |
| 3 | 4 | Developer |
そして、「$+数字」という形で、データが取得されます。
- $0:レコード全体を表示する。
- $1:1番目のフィールドの表示。つまり、1列目のデータをとってくる。
- $2:2番目のフィールドの表示。つまり、2列目のデータをとってくる。
- ・・・
2.3. パターンとアクションの構成
- パターン部分は正規表現や条件式を使用できます。例えば、
$3 > 100のように、3列目の値が100より大きい行を条件にできます。 - アクション部分には
print、printf、変数の操作、ループ構文などを記述可能です。
例:
awk '$3 == "INFO" { print $1, $3 }' logfile.txtこのコマンドは、2列目が”INFO”の行に対し、1列目と3列目を表示します。
2.4. BEGINとENDセクションの役割
- BEGIN: ファイルの処理が始まる前に実行する処理を記述します。主にヘッダーの出力や初期設定に使われます。
- END: ファイルの全行の処理が終わった後に実行される処理を記述します。集計結果やフッターの出力に利用されます。
例:
awk 'BEGIN { print "開始"; sum=0 } { sum += $2 } END { print "合計:", sum }' data.txtこのスクリプトは、データの2列目を合計し、最初に「開始」、最後に合計値を出力します。

3. 基本的な使い方
3.1. テキストファイルのデータ処理
AWKは、行単位の処理や列の操作に特化しており、以下のような操作が可能です:
- ファイルの各行を読み取り、条件に基づいて処理を実行。
- 必要な情報だけを抽出して新しい形式で出力。
例:
awk '{ print NR, $0 }' sample.txtこれは、各行に行番号を追加して出力します。
3.2. 特定の列の抽出
AWKでは、$1、$2といった形式で列を指定できます。
$0は行全体を表します。$1は1列目、$2は2列目…というように指定可能。
例:
awk '{ print $1 }' data.txtこのコマンドは、1列目を抽出して出力します。
3.3. 条件に基づく行の抽出 (ifや/pattern/)
AWKでは、if文や正規表現を用いた条件指定ができます。
3.3.1. 例1: 数値条件
awk '$3 > 100 { print $0 }' data.txt3列目の値が100を超える行を抽出します。
3.3.2. 例2: 正規表現
awk '/ERROR/ { print $0 }' logfile.txt“ERROR”を含む行を抽出します。
4. AWKの出力処理
4.1. 標準出力の基本
AWKはテキスト処理のためのプログラム言語で、行ごとに特定のカラムやパターンに基づいてデータを処理できます。以下は簡単な例です:
# ファイル内の第1カラムを出力
awk '{print $1}' data.txtこの例では、data.txtの各行の1番目のフィールド(カラム)を標準出力に表示しています。

4.2. printとprintfの使い分け
printはデフォルトの改行付き出力を行いますが、printfはC言語に似たフォーマット指定を可能にします。
# 第1カラムと第2カラムをタブ区切りで出力
awk '{print $1 "\t" $2}' data.txt
# 第1カラムを右詰めで出力
awk '{printf "%10s\n", $1}' data.txt
printfを使用すると、出力結果を整形して見やすくすることができます。
4.3. カスタマイズされた出力フォーマット
printfでは、特定のフォーマットを指定できます。たとえば、数値を小数点以下2桁まで表示するなどが可能です。
# 第1カラムと第2カラムをカンマ区切りで出力し、第2カラムは小数点以下2桁にフォーマット
awk '{printf "%s, %.2f\n", $1, $2}' data.txt
5. 便利な組み込み関数
AWKには、データ処理を効率化するための便利な組み込み関数が数多く用意されています。ここでは、数値演算、文字列操作、配列操作の基本を紹介します。
5.1. 数値演算関数
AWKは単なるテキスト処理だけでなく、数値計算も得意です。以下のような組み込み関数を使用することで、簡単に数値演算を実行できます。
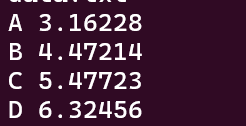
sqrt(x): 数値xの平方根を計算。awk '{ print $1, sqrt($2) }' data.txt例: 2列目の平方根を計算。
int(x): 数値xを整数に切り捨てる。awk '{ print $1, int(sqrt($2)) }' data.txt例: 2列目の数値を整数に変換して出力。

rand(): 0から1の間の乱数を生成。awk 'BEGIN { print rand() }'例: 乱数を1つ生成。

5.2. 文字列操作関数
AWKでは、文字列の操作も簡単に行えます。以下は代表的な関数です。
length(str): 文字列strの長さを取得。awk '{ print $3, length($3) }' logfile.txt例: 3列目の文字列の長さを表示。

substr(str, start, length): 文字列strのstart位置からlength文字分を取得。awk '{ print substr($3, 1, 3) }' logfile.txt例: 3列目の先頭3文字を抽出。
tolower(str)/toupper(str): 文字列strを小文字または大文字に変換。awk '{ print tolower($3), toupper($3) }' logfile.txt例: 小文字、大文字に変換。
5.3. 配列操作の基本
AWKでは配列を簡単に扱うことができ、キーと値のペアを用いた連想配列が利用可能です。
- 配列への値の格納と取得 例: 1列目をキー、2列目を値として格納し、値の内容を2倍にして出力。
awk '{ arr[$1] = $2 } END { for (key in arr) print key, arr[key]*2 }' data.txt
6. AWKスクリプトの作成と実行
AWKを利用する際には、コマンドラインから直接実行する方法と、スクリプトファイルを作成して再利用可能にする方法があります。
6.1. スクリプトファイルの作成と実行
再利用性を高めるため、AWKスクリプトをファイルとして保存することができます。
- スクリプトファイルを作成します(例:
script.awk)。BEGIN { print "Processing Start" } { print $1, $2 } END { print "Processing End" } - 以下のように実行します。
awk -f script.awk data.txt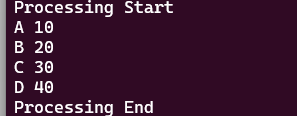
6.2. シェルスクリプトとの組み合わせ
AWKはシェルスクリプトと組み合わせることで、さらに強力なデータ処理が可能です。
#!/bin/bash
for file in *.txt; do
awk '{ print $1, $NF }' "$file"
done例: ディレクトリ内のすべての.txtファイルに対して、1列目と最終列を抽出。
7. AWK特有の記号
AWK には、テキストの行数・フィールド数・区切り文字などを管理するために「ビルトイン変数 (組み込み変数)」が次のように用意されています。
- NR: 全体の行番号(通し番号)
- NF: 現在行のフィールド数
- FNR: 現在ファイルの行番号(ファイルごとにリセット)
- RS: 入力のレコード区切り文字(デフォルトは改行)
- FS: フィールド区切り文字(デフォルトは空白)
- OFS: 出力のフィールド区切り文字(デフォルトは空白)
7.1. NR
- 意味 現在までに処理した「入力行数」を表します。
- 使用例 上記の例では、NR とともにその行の内容($0)が表示されます。
# 各行が何行目なのか表示する awk '{ print NR, $0 }' sample.txt
7.2. NF
- 意味 現在の行の「フィールド数」を表します。(各行がいくつのフィールドに分割されているか)
- 使用例 各行について、フィールド数(NF)と行の内容($0)が表示されます。
# 各行のフィールド数を表示する awk '{ print NF, $0 }' file.txt

7.3. FNR
- FNR の意味 複数ファイルを入力に指定した場合、各ファイルごとにリセットされる「ファイル内の現在の行数」を表します。
- 使用例 2つのファイルを連続で処理したとき、FNR は各ファイルの先頭行から 1, 2, 3… とカウントされます。
# 各ファイルごとに行番号を付与して表示 awk '{ print FNR, $0 }' sample.txt logfile.txt
7.4. RS
- 意味 レコードセパレータ (Record Separator)。入力を「行」や「レコード」に分割するときに使われる区切り文字列。
- デフォルト値 改行文字 (
"\n") - 使用例 空行を境界としてまとまったテキストが1レコードとして扱われ、NR でそれぞれのレコード番号が示されます。
# 空行をレコードセパレータとする例(2行以上のまとまりを1レコードとして扱う) awk 'BEGIN { RS="" } { print NR, $0 }' sample.txt
7.5. FS
- 意味 フィールドセパレータ (Field Separator)。1行(レコード)を複数のフィールドに分割するときの区切り文字列。
- デフォルト値
" "(空白文字; 実際には空白文字が連続した場合でも1つの区切りとみなす) - 使用例 1行をカンマで区切ったフィールド($1, $2, $3, …)を処理できます。
# カンマ区切りのファイル(CSV)を処理するとき awk 'BEGIN { FS="," } { print $1, $2, $3 }' data.csv
7.6. OFS
-
- 意味 出力の際に各フィールドの間に挿入する文字列 (Output Field Separator)。
- デフォルト値
" "(半角スペース) - 使用例 入力はカンマ区切り(FS=”,”)、出力時にはフィールド間を縦棒
|(OFS=”|”) で区切るようになります。awk 'BEGIN { FS=","; OFS="|" } { print $1, $2, $3 }' data.csv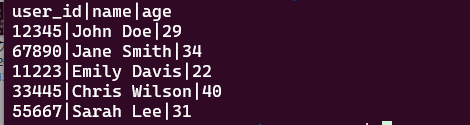
8. 条件分岐とループ
AWKには条件分岐や繰り返し処理のための構文が備わっています。これにより、柔軟なスクリプトを記述できます。
8.1. if-else文の使い方
条件に応じて処理を分岐させる場合、if-else文を使用します。
awk '{ if ($2 > 20) print $1, "High"; else print $1, "Low" }' data.txt例: 2列目が20より大きい場合に”High”、それ以外は”Low”と表示。

複数条件の場合:
awk '{
if ($2 > 30) print $1, "High";
else if ($2 > 20) print $1, "Medium";
else print $1, "Low";
}' data.txt
8.2. forやwhileループによる繰り返し処理
ループを利用することで、データ全体の集計や加工が可能です。
forループawk '{ for (i=1; i<=NF; i++) print $i }' data.txt例: 各行のすべての列を出力。

whileループawk '{ i = 1; while (i <= NF) { print $i; i++; } }' data.txt例: 各列を1つずつ出力。

9. CSVファイルの処理
CSV(カンマ区切り形式)は、データの保存や共有に広く使われている形式です。AWKを使用することで、CSVファイルを簡単に処理できます。
9.1. 特定の列を抽出
以下の例では、CSVファイルの1列目と3列目を抽出して表示します。
awk -F, '{ print $1, $3 }' data.csv
F,オプションを使用してカンマを区切り文字として指定しています。
9.2. 条件付きで行を抽出
特定の条件に一致する行だけを抽出できます。
awk -F, '$2 > 100 { print $0 }' data.csv
- 2列目の値が100を超える行を抽出。
9.3. 新しいCSVファイルの作成
抽出したデータを新しいCSVファイルとして保存できます。
awk -F, '$3 == "OK" { print $1 "," $2 }' data.csv > filtered.csv
- 3列目が”OK”の行を抽出し、カンマ区切りで出力。
10. ログファイルの解析
ログファイルの解析は、AWKが得意とする用途の一つです。以下に、実用的な例をいくつか示します。
10.1. エラー行の抽出
ログファイルから、エラー行だけを抽出する例です。
awk '/ERROR/ { print $0 }' logfile.txt
- “ERROR”を含む行をすべて表示。
10.2. 特定の時間帯のログを抽出
ログファイルの日時情報を解析して、特定の時間帯のログを抽出します。
awk '$1 == "2024-12-29" && $2 ~ /^10:/ { print $0 }' logfile.txt- 2024年12月29日の10時台のログを抽出。

10.3. ログの集計
ログの中で、特定のキーワードが何回出現しているかを集計します。
awk '/ERROR/ { count++ } END { print "ERROR count:", count }' logfile.txt
- “ERROR”が出現した回数をカウント。
![]()
11. データの集計と統計処理
AWKは、データを集計して統計情報を生成するのにも役立ちます。
11.1. 合計と平均値の計算
数値データの合計と平均値を計算します。
awk '{ sum += $2; count++ } END { print "Sum:", sum, "Average:", sum / count }' data.txt
- 2列目の値を合計し、平均値を計算。
![]()
11.2. 最大値と最小値の計算
データセットの中で最大値と最小値を特定します。
awk 'NR == 1 || $2 > max { max = $2 } NR == 1 || $2 < min { min = $2 } END { print "Max:", max, "Min:", min }' data.txt
- 2列目の最大値と最小値を計算。
![]()
11.3. ヒストグラムの作成
データを区間ごとに分けて頻度を集計します。
awk '{ bin = int($2/ 10) * 10; freq[bin]++ } END { for (b in freq) print b, "-", b+9, ":", freq[b] }' data.txt
- 10の倍数ごとにデータを区切り、頻度を表示。





