bert-base-uncasedの使い方!マスクされた単語を推測する!

1. BERTとは
- Encoderタイプのモデル
- not case-sensitive
- 110M params
- 英語で事前学習
BERT(Bidirectional Encoder Representations from Transformers)はencoderのみのモデルです。bert-base-uncased はbertの一種で、MLMを用いて英語を対象に事前学習を行われています。bert-base-uncasedは110M paramsです。bert-base-casedというモデルもありますが、bert-base-casedはcase-sensitiveなモデルになっています。つまり、Japanaとjapanは違います。一方で、今回使用するbert-base-uncasedはJapanaとjapanは同じです。


2. bert-base-uncasedでできること
MLM(Masked Language Modeling)と呼ばれるマスクされた位置に何の単語が入るべきかを予測します。
2.1. MLMの流れ
- 単語のマスキング
- 選ばれた単語はマスクトークン(通常は
[MASK]トークン)に置き換えられます。例えば、「The quick brown fox jumps over the lazy dog」という文があった場合、「The quick [MASK] fox jumps over the [MASK] dog」のように一部の単語がマスクされます。
- 選ばれた単語はマスクトークン(通常は
- マスクされた文をモデルに入力
- マスクされた文がBERTモデルに入力されます。モデルはこのマスクされた文を通して、マスクされた単語を予測します。
- マスクされた単語の予測
- モデルは、マスクされた位置に何の単語が入るべきかを予測します。例えば、マスクされた位置に「brown」や「lazy」が元々入っていたことを予測します。
2.2. MLMの目的
MLMの目的は、モデルに双方向的な文の理解を持たせることです。従来のリカレントニューラルネットワーク(RNN)や自己回帰モデル(例えばGPT)は、文を一方向にしか見ることができません。これに対して、MLMでは文全体を一度に処理し、文の前後の文脈情報を同時に考慮します。
3. pythonコード
3.1. 実行環境
- RTX 4070ti super
- Windows11
- memory 64GB
- Python 3.11.9
3.2. python
次のプログラムは、Hugging FaceのTransformersライブラリを使用して、BERTモデルでマスク化言語モデリング(Masked Language Modeling, MLM)を実行しています。具体的には、指定された文中のマスクされた部分を予測します。
from transformers import pipeline,set_seed
set_seed(42)
pipe = pipeline('fill-mask', model='bert-base-uncased')
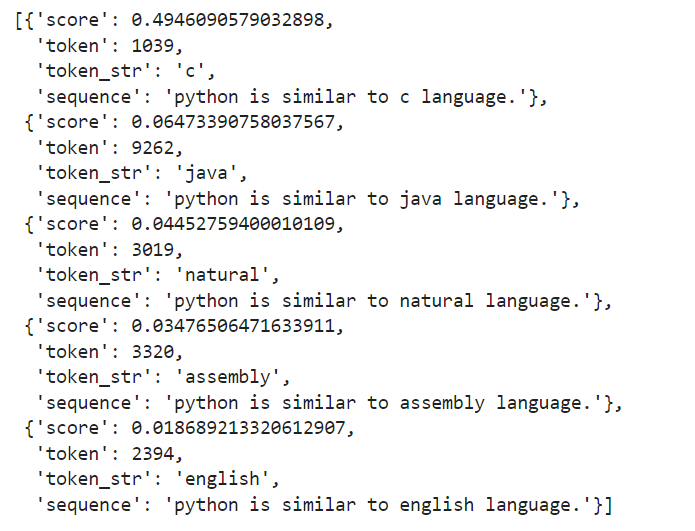
out=pipe("python is similar to [MASK] language.")
print(out)入力文 “python is similar to [MASK] language.” をモデルに渡します。文中の [MASK] トークンが予測対象となります。モデルはこのマスクされた単語を予測します。
BERTによると、C言語の確率が最も高くや次にJavaであることがうかがえます。
3.3. Case-Sensitiveでないことの確認
bert-base-uncasedはCase-Sensitiveでないので、pythonをPythonにしても同じ結果が返ってくるはずです。確認してみましょう!
from transformers import pipeline,set_seed
set_seed(42)
pipe = pipeline('fill-mask', model='bert-base-uncased')
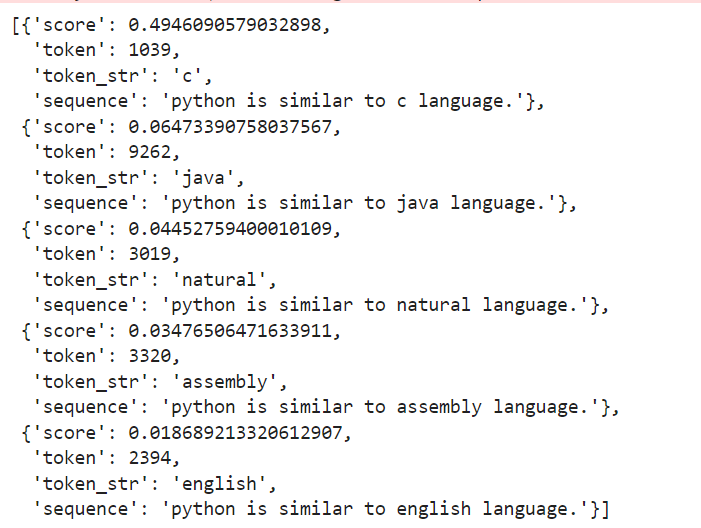
out=pipe("Python is similar to [MASK] language.")
outシード値を固定しているので同じ結果が得られました。
3.4. 使用された計算資源