bert-large-uncased を使ってみよう!MLMを試す!



1. BERTとは
- Encoderタイプのモデル
- case-sensitiveでない
- 336M params
- 英語で事前学習
- 24層のレイヤー
- 隠れ層が1024次元
- アテンションヘッドが16個
BERT(Bidirectional Encoder Representations from Transformers)はencoderのみの言語モデルです。bert-large-uncased はbertの一種で、MLMを用いて英語を対象に事前学習を行われています。bert-large-uncased は336M paramsです。bert-large-uncased はcase-sensitiveではないので、大文字小文字を区別しないです。例えば、Japanaとjapanは同じであると扱われます。また、bert-base-uncasedという110M paramsの言語モデルもあります。
2. bert-large-casedでできること
MLM(Masked Language Modeling)と呼ばれるマスクされた位置に何の単語が入るべきかを予測します。
2.1. MLMの流れ
- 単語のマスキング
- 選ばれた単語はマスクトークン(通常は
[MASK]トークン)に置き換えられます。例えば、「The cat is sleeping peacefully on the couch, curled up in a cozy ball, with the sunlight streaming through the window and warming its fur.」という文があった場合、「The [MASK] is sleeping peacefully on the couch, curled up in a cozy ball, with the sunlight streaming through the window and warming its fur.」のように一部の単語がマスクされます。
- 選ばれた単語はマスクトークン(通常は
- マスクされた文をモデルに入力
- マスクされた文がBERTモデルに入力されます。モデルはこのマスクされた文を通して、マスクされた単語を予測します。
- マスクされた単語の予測
- モデルは、マスクされた位置に何の単語が入るべきかを予測します。例えば、マスクされた位置に「cat」が元々入っていたことを予測します。
2.2. MLMの目的
MLMの目的は、モデルに双方向的な文の理解を持たせることです。従来のリカレントニューラルネットワーク(RNN)や自己回帰モデル(例えばGPT)は、文を一方向にしか見ることができません。これに対して、MLMでは文全体を一度に処理し、文の前後の文脈情報を同時に考慮します。
3. pythonコード
3.1. 実行環境
- RTX 4070ti super VRAM 16GB
- Windows11
- memory 64GB
- Python 3.11.9
3.2. python
次のプログラムは、Hugging FaceのTransformersライブラリを使用して、BERTモデルでマスク化言語モデリング(Masked Language Modeling, MLM)を実行しています。具体的には、指定された文中のマスクされた部分を予測します。
from transformers import pipeline,set_seed
set_seed(42)
pipe = pipeline('fill-mask', model='bert-large-cased',device=0)
out=pipe("The [MASK] is sleeping peacefully on the couch, curled up in a cozy ball, with the sunlight streaming through the window and warming its fur.")
out入力文 “The [MASK] is sleeping peacefully on the couch, curled up in a cozy ball, with the sunlight streaming through the window and warming its fur.” をモデルに渡します。文中の [MASK] トークンが予測対象となります。モデルはこのマスクされた単語を予測します。
今回はマスクされた単語が、「cat」であることを予測することができました。

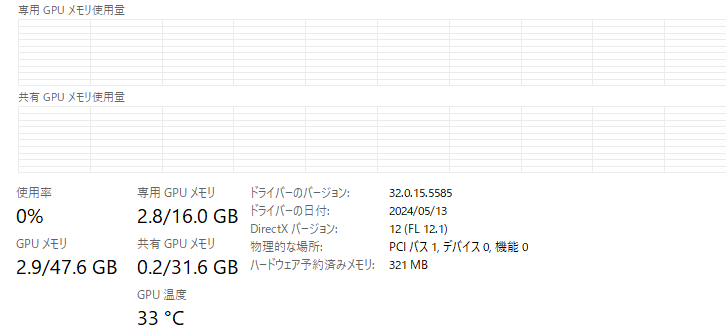
3.3. 使用された計算資源
4. Transformers・大規模言語モデルに関連する書籍
-
【Transformers】SwallowをHugging Faceで使う方法

-
huggingfaceの.cacheの肥大化!シンボリックリンクで解決!
-
-
【深層学習】Dying ReLU問題とReLU(Rectified Linear Unit)について

-
【Transformers】エラーValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token`・・・・解決方法

-
【scikit-learn】決定木による分類の意味と使い方について
