更新:2024/07/22
PythonでDatasetsのmapメソッドを使ったデータ整形の方法

はるか
Pythonの
datasetsライブラリのmapメソッド知ってる?
ふゅか
もちろん!データ整形には便利よね。
1. Datasetsのmap
datasetsライブラリのmapメソッドは、データセット内の各サンプルに関数を適用するために使用されます。これにより、データセットを前処理したり、特定の操作を実行することができます。以下に基本的な使い方を説明します。
2. Pythonの基本的な使い方
2.1. インストール
まず、datasetsライブラリをインストールします。
pip install datasets
2.2. データセットのロード
次に、データセットをロードします。ここでは、google/spiqaデータセットを例として使用します。
from datasets import load_dataset
# データセットのロード
ds=load_dataset("google/spiqa")
データセットの特徴は次のようになっています。

ふゅか
データセットをロードするのも簡単!load_datasetを使うだけ。
はるか
うん、google/spiqaを例に使用する。
2.3. 関数の定義
mapメソッドに渡す関数を定義します。この関数はデータセットの各サンプルに対して実行されます。bert-base-casedを使用してテキストのトークン化を行います。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")# 例: トークナイズを行う
def tokenize_function(example):
return tokenizer(example['text'], padding='max_length', truncation=True)
mapメソッドをデータセットに対して適用した場合、exampleが各サンプルとなります。
はるか
トークナイザーも必要。AutoTokenizer.from_pretrainedを使用する。
ふゅか
今回はbert-base-casedでトークン化も簡単にできるのよ。
2.4. mapメソッドの適用
mapメソッドを使用して、データセットの各サンプルに対して関数を適用します。
tokenized_datasets = ds.map(tokenize_function, batched=True)
batched=Trueを設定すると、関数がバッチで呼び出され、処理が高速化されます。
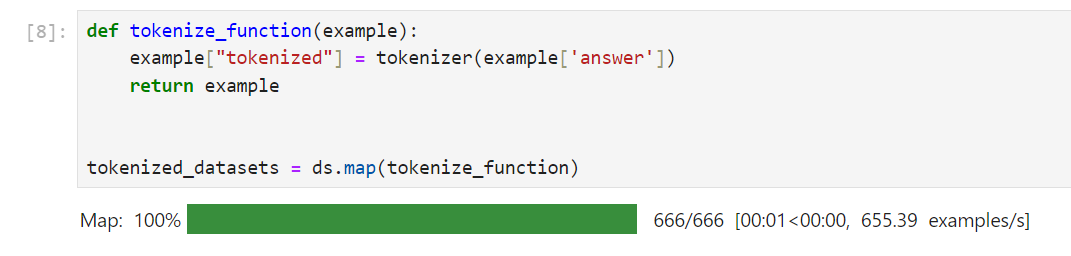
追加したカラムは次のようにトークン化したものであることを確認できます。

このようにして、datasetsライブラリのmapメソッドを使用することで、データセットの前処理や操作を簡単に行うことができます。
PR




.png.webp)