更新:2024/10/07
スパコン「富岳」で学習したFugaku LLMをHugging Faceからダウンロードして使う方法


はるか
Fugaku-LLMを知ってる?日本のスーパーコンピュータ「富岳」で学習した大規模言語モデル。

ふゅか
知ってるわ!日本語のLLMだね♪
目次
1. Fugaku LLMとは?
Fugaku-LLMは、日本のスーパーコンピュータ「富岳」を活用した大規模言語モデルです。このモデルは、特に日本語の自然言語処理において高い性能を発揮することが期待されています。Fugaku-LLMは東京工業大学、東北大学、富士通、理化学研究所、名古屋大学、サイバーエージェント、Kotoba Technologiesの共同研究チームによって開発された。
2. Hugging Faceの設定
2.1. Hugging Faceの認証トークン取得
Fugaku-LLMを利用するためにはトークンが必要です。Hugging Faceのトークンを取得するために、以下の手順に従ってください。
- Hugging Faceのウェブサイトにアクセスし、アカウントを作成またはログインします。
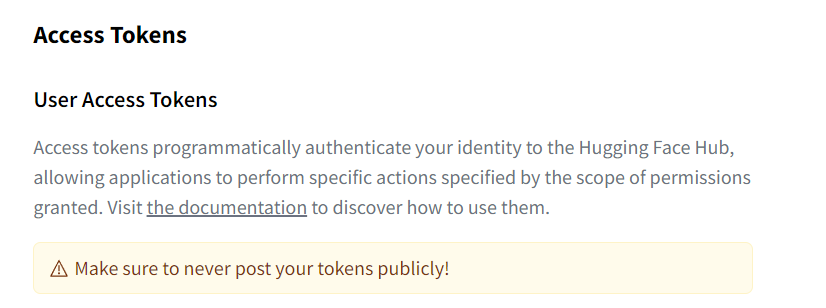
- プロフィールアイコンをクリックし、
Settingsを選択します。 Access Tokensセクションに移動し、新しいトークンを作成します。トークンには名前とwriteの権限を設定してください
はるか
トークンは流出しないように。
2.2. モデルのアクセス権限を確認
Fugaku-LLMのモデルにアクセスするために、アクセス権限が必要です。Hugging FaceのFugaku-LLMのリポジトリでアクセス権限を取得してください。
ふゅか
アカウントでログインしている必要があります!
モデルのアクセス権限がないと、「Access to model Fugaku-LLM/Fugaku-LLM-13B-instruct is restricted. You must be authenticated to access it.」となります。

はるか
Fugaku-LLMのリポジトリでアクセス権限を取得する必要がある。
ふゅか
そうね、アクセス権限がないとモデルが使えないから、忘れずにリクエストしないとね♪
3. Fugaku LLMを動かす
3.1. Tokenの設定
Tokenに先ほど設定したトークンを入力して使用します。
from huggingface_hub import login
# Hugging Faceにログイン
login()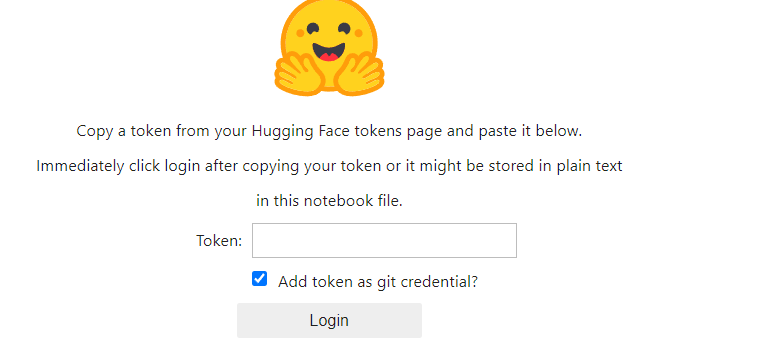
Tokenの入力に成功すると次のようになります。

3.2. Fugaku LLMを使用した文章生成
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルのパスを設定
model_path = "Fugaku-LLM/Fugaku-LLM-13B-instruct"
# トークナイザーのロード
tokenizer = AutoTokenizer.from_pretrained(model_path)
# モデルのロード
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16)
model.eval()
# システムの例と指示の例を設定
system_example = "以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。"
instruction_example = "あなたの今日の晩御飯の気分を教えてください。"
# プロンプトを作成
prompt = f"{system_example}\n\n### 指示:\n{instruction_example}\n\n### 応答:\n"
# 入力IDをトークナイズ
input_ids = tokenizer.encode(prompt,
add_special_tokens=False,
return_tensors="pt")
# テキストを生成
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
do_sample=True,
temperature=0.1,
top_p=1.0,
repetition_penalty=1.0,
top_k=0
)
# 生成されたトークンをデコード
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
ふゅか
どうやら、今日の晩御飯の気分はタイカレーのようだね!
4. Transformers・大規模言語モデルに関連する書籍
ブックオフ2号館 ヤフーショッピング店
bookfanプレミアム
大規模言語モデル入門II-生成型LLMの実装と評価 / 山田育矢 〔本〕
posted with カエレバ
HMV&BOOKS online Yahoo!店
PR



