【深層学習】Leaky ReLU(Leaky Rectified Linear Unit)の意味と性質について


1. Leaky ReLUとは?
Leaky ReLU(LReLU、Leaky Rectified Linear Unit)は、標準のReLU(Rectified Linear Unit)を改良したものです。ReLUは、入力が正の数ならそのまま出力し、負の数なら0を返すというシンプルな活性化関数ですが、この場合「負の入力が続くと、特定のニューロンが学習を停止する」という問題があります。これを「dying ReLU」問題と呼びます。
1.1. Leaky ReLUの仕組み
Leaky ReLUは、負の入力に対しても少しだけ出力を返すように改良されています。具体的には、負の入力があったときに、通常は入力の0.01倍(または他の小さい値)を出力します。数式で表すと、次のようになります。
Leaky ReLUは、負の入力にもわずかな勾配を与えるため、「死んだニューロン(出力が常にゼロになるニューロン)」が発生しにくくなり、学習が停滞することを防ぎやすくなります。さらに、2015年に発表された「Empirical Evaluation of Rectified Activations in Convolutional Network」という論文では、画像分類タスクにおいて、Leaky ReLUが通常のReLUよりも優れた精度を実現することが示されました。

2. Leaky ReLUの微分
Leaky ReLU関数は \( x = 0 \) の点で微分可能ではありません。しかし、ニューラルネットワークなどの応用では、実装上の単純化やアルゴリズム上の理由から、あえて「形式的に」以下のように記述します。
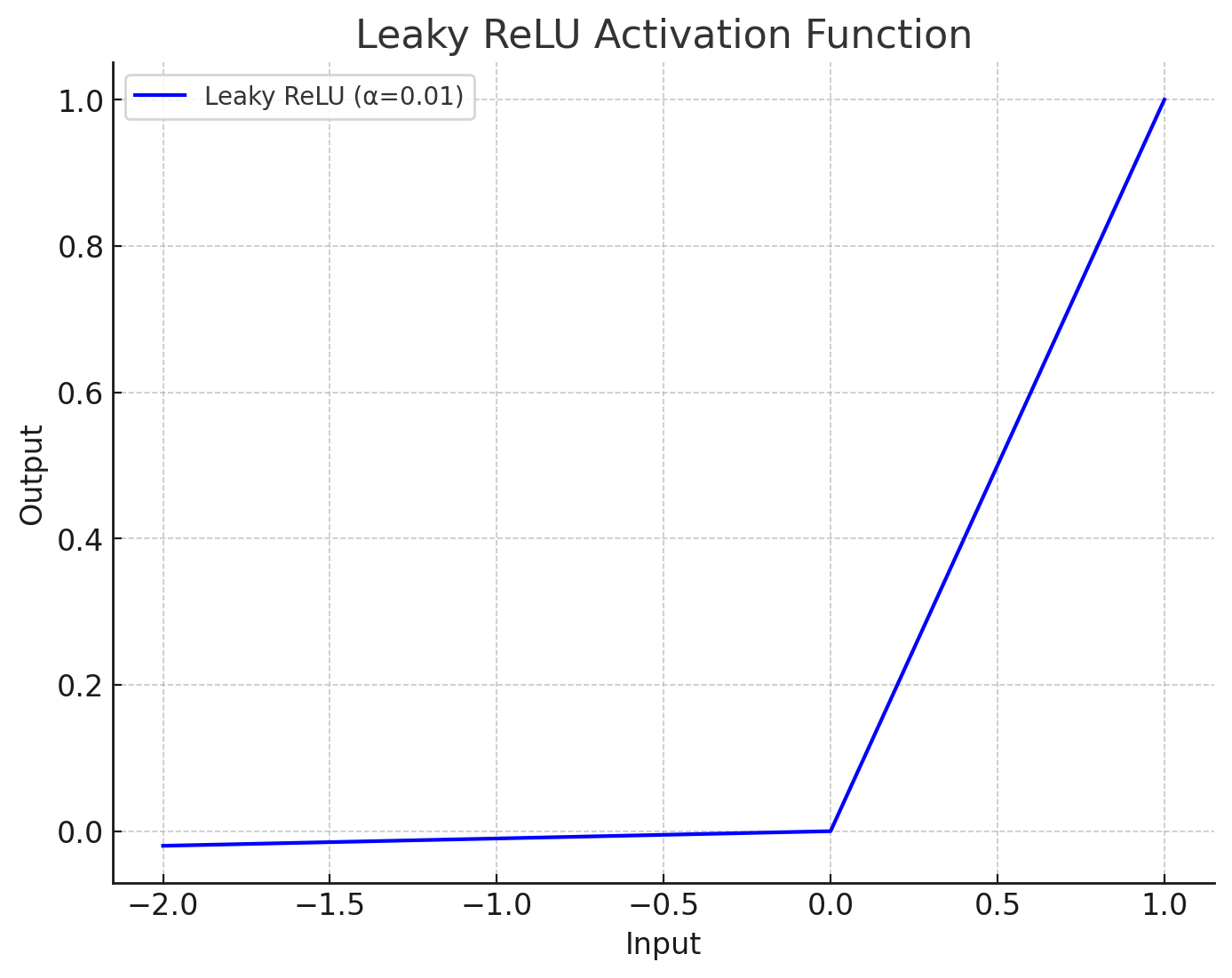
3. Leaky ReLUのグラフ
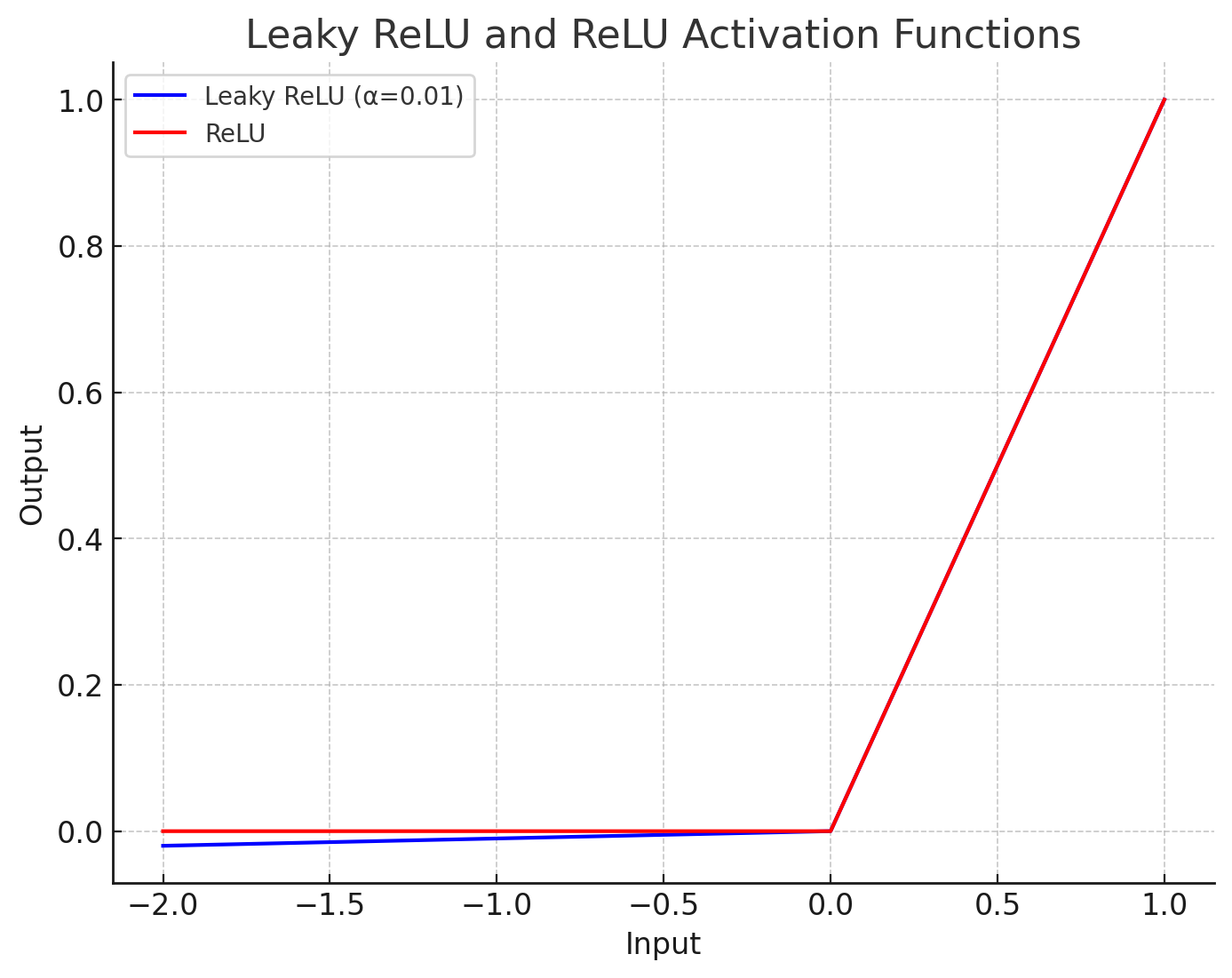
Leaky ReLUの特徴を理解するために、グラフを見てみましょう。
さらに、ReLUとLeaky ReLUを同じグラフ上に並べると、それぞれの違いがより明確に分かります。ReLUはゼロ以下の入力に対して常にゼロを返すため、グラフ上でゼロ以下の部分は水平線になります。一方、Leaky ReLUはわずかに負の傾きがついているため、ゼロ以下の入力でも少しずつ負の値を出力します。