大規模言語モデルにおけるpadding_token[PAD]の意味について



1. pad_tokenとは?
pad_token(パッドトークン)は、自然言語処理(NLP)やディープラーニングで使用される重要な要素です。主にテキストデータをモデルに入力する際に使われる特別なトークンで、テキストデータのサイズを揃えるために役立ちます。では、具体的にどのような場面で使われ、どんな意味を持つのかについて詳しく説明していきましょう。
1.1. pad_tokenの役割
モデルにテキストデータを入力する際、文章ごとに長さ(単語数や文字数)が異なります。そこで、すべての文章の長さを同じにするために短い文章の末尾に「パッド」を追加します。この「パッド」の役割を果たすのがpad_tokenです。例えば、以下のような例を考えてみます。
文1:I like cats.
文2:I like also dogs.
文2の単語数が4つ、文1が3つの場合、文1には1つのpad_tokenを加えて、長さを揃えます。これにより、すべての文章が同じサイズになり、モデルへの入力がスムーズになります。
1.2. padding_token
pad_tokenは「padding token(パディングトークン)」とも呼ばれます。日本語で「パディング」とは「埋め合わせ」や「詰め物」といった意味を持ち、データの長さを統一するために使われるトークンです。通常、自然言語処理で異なる長さのテキストデータを揃える際に、余白部分を埋める目的で利用されます。
2. pad_tokenが使われる理由
バッチ処理と呼ばれる複数のデータを一度に処理する手法では、入力サイズが固定・統一されていることが求められる場合があります。pad_tokenを使ってデータの長さを揃えることで、無駄な計算を避け、効率的な学習が可能になります。
2.1. pad_tokenの注意点
- 無視される部分:
pad_tokenはモデルにとって有用な情報ではありません。そのため、モデルはpad_token部分を無視する仕組みが組み込まれている場合があります。これにより、計算に影響を与えず、必要なデータのみを使って学習が行えます。 - 不具合の原因になる場合も:
pad_tokenの扱いが適切でない場合、学習モデルが不安定になることがあります。
3. Transoformersのpad_tokenの設定方法
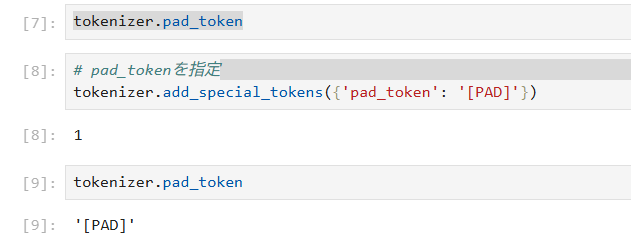
多くのNLPライブラリではpad_tokenの指定が可能です。例えば、Hugging FaceのTransformersライブラリでは、pad_token_idを指定してモデルに入力する際、どのトークンがpad_tokenであるかを認識させます。この設定により、モデルは自動的にpad_tokenを無視し、実際のデータのみを処理することができます。また、pad_tokenは設定されてる場合と設定されていない場合があります。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Meta-Llama-3-8B')
# pad_tokenを指定
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
4. まとめ
pad_tokenは、モデルに入力するデータの長さを統一するために使われる重要なトークンです。これにより、効率的なバッチ処理や計算が可能になりますが、設定を誤ると学習が不安定になるリスクもあります。モデルの学習や推論をスムーズに進めるため、pad_tokenの役割を正しく理解し、適切に使うことが重要です。




