更新:2024/10/11
meta-llama/Meta-Llama-3-8Bの使い方!導入から活用までの徹底解説


ふゅか
ねえ、ふゅか、Llama-3って聞いたことある?

はるか
うん、Metaが開発した大規模言語モデル。
目次
1. meta-llama/Meta-Llama-3-8Bとは
- decoderタイプのモデル
- 8.03Bのパラメータ
- 入力はテキストのみ
- 出力はテキスト
Meta-Llama-3-8Bは、Metaが開発したdecoderタイプの大規模言語モデルです。テキスト生成やード補完、対話システムに優れ、8Bと70Bのパラメータサイズがあります。Llama3(ラマスリー)をベースにした様々なモデルも登場しています。例えば、rinna/llama-3-youko-8bやelyza/Llama-3-ELYZA-JP-8Bなどがあります。
Llama3を使うためには、許可が必要なのでhugging faceでレポジトリのアクセスの許可をもらいましょう。
2. pythonコード
2.1. 実行環境
- RTX 4070ti super VRAM 16GB
- Windows11
- memory 64GB
- Python 3.11.9
2.2. pipelineのコード
from transformers import pipeline
pipe = pipeline("text-generation", model="meta-llama/Meta-Llama-3-8B",device_map="auto")2.3. モデルを直接読み込む方法
モデルを4ビット精度でロードして、メモリ使用量を削減しています。
from transformers import AutoTokenizer, AutoModelForCausalLM,set_seed
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B"
,device_map="auto"
,load_in_4bit=True)
set_seed(42)
prompt="If I were to become a wizard, "
input_ids = tokenizer.encode(prompt,return_tensors="pt").to("cuda")
generated_token = model.generate(input_ids,
max_new_tokens=128,
)
out = tokenizer.decode(generated_token[0], skip_special_tokens=True)
print(out)
2.3.1. 出力結果
If I were to become a wizard, 1st thing I'd do is find a way to get a dragon to pull my wagon. I am very glad that I'm not a wizard. That would be a nightmare. I would be a wizard, but I'd be a wizard who didn't have any powers. I'd be a wizard who's just really good at explaining things.
もし僕が魔法使いになったら、まず最初にすることは、ドラゴンを見つけて自分の荷車を引かせることだろう。 魔法使いじゃなくて本当に良かった。そんなの悪夢だよ。 僕は魔法使いになるけれど、魔法の力を持っていない魔法使いになるんだ。ただ、説明がとても上手な魔法使いになるよ。
はるか
自分で荷車を引かせているくせに、悪夢だと言ってる。
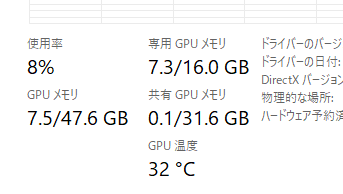
2.4. 使用された計算資源
3. Transformers・大規模言語モデルに関連する書籍
ブックオフ2号館 ヤフーショッピング店
bookfanプレミアム
大規模言語モデル入門II-生成型LLMの実装と評価 / 山田育矢 〔本〕
posted with カエレバ
HMV&BOOKS online Yahoo!店
PR

.png.webp)
