更新:2024/09/28
meta-llama/Llama-3.2-1Bの使い方について【天ぷらが好きか聞くと・・・】


ふゅか
Metaの新しいモデル、Llama-3.2-1Bについて知ってる?

はるか
軽量な言語モデルらしい。
1. meta-llama/Llama-3.2-1Bとは
- decoderタイプのモデル
- 1.24B のパラメータ
- テキスト生成の言語モデル
Llama-3.2-1Bは、Metaが開発したdecoderタイプの大規模言語モデルです。1B以外にも、3Bのサイズのモデルがあります。「英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語」の8つの言語をサポートしていると公式は述べています。テキスト生成やコード補完、対話システムなどの使用が考えられます。また、過去に解説した、Llama-3と比較して、軽量なモデルであることが特徴です。また、画像認識などに関連するvision系の11Bと90Bのllama-3.2も登場したようです。
Llama-3.2-1Bを使うためには、Llama-3と同様に許可が必要なのでhugging faceでレポジトリのアクセスの許可をもらいましょう。
2. pythonコード
はるか
今回はLlama-3.2-1Bに天ぷらがすきなのかどうか聞いてみる。
2.1. 実行環境
- RTX 4070ti super VRAM 16GB
- Windows11
- memory 64GB
- Python 3.11.9
2.2. pipelineを使用したコード
import torch
import transformers
model_id = "meta-llama/Llama-3.2-1B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt="Do you like tempura? \n"
out=pipeline(prompt)
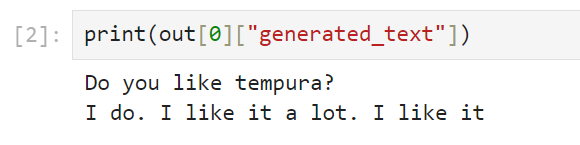
print(out[0]["generated_text"])普通に受け答えをしてくれました。「I do. I like it a lot. I like it」と、天ぷらに対して好印象らしいですね。
はるか
普通に答えてくれる。「好きだ」って。
2.3. モデルを直接読み込む方法
今回はモデルが比較的軽量なので量子化せず、普通に読み込みます。また、do_sample=Trueとして、サンプリングを行います。
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import set_seed
import torch
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-1B")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-1B",
device_map="auto",
torch_dtype=torch.bfloat16
)
set_seed(50006)
prompt="Do you like tempura?"
input_ids = tokenizer.encode(prompt,return_tensors="pt").to("cuda")
generated_token = model.generate(input_ids,max_new_tokens=100,
do_sample=True, top_k=50)
out = tokenizer.decode(generated_token[0], skip_special_tokens=True)面白いことに、言語モデルは質問を答える側ではなく、聞く側としてとらえたようで、すしのデリバリーをおすすめしてきました。
Do you like tempura? Is it your favorite cuisine?
Try this sushi box lunch delivery!
These are all made fresh on location!
Sake, beer, wine and more!
PR




