【深層学習】ニューラルネットワーク(NN)の基礎知識について



1. ニューラルネットワークとディープニューラルネットワーク
近年、人工知能(AI)と機械学習の分野でニューラルネットワーク(Neural Network, NN)が注目を集めています。ニューラルネットワークは、人間の脳の神経回路を模倣した計算モデルであり、画像認識や自然言語処理など、多岐にわたる分野で活用されています。また、ディープラーニング(深層学習)は、多層のニューラルネットワーク(ディープニューラルネットワーク)を用いた機械学習の一形態です。「ディープ」という言葉は、多くの隠れ層(複数のニューロンの層)があることを指します。
2. ニューラルネットワークの構成
2.1. ノード(ニューロン)
〇はノードまたはニューロンと呼ばれ、各ノードは複数の入力を受け取り、特定の関数を適用して出力を生成します。この特定の関数のことを活性化関数と呼びます。
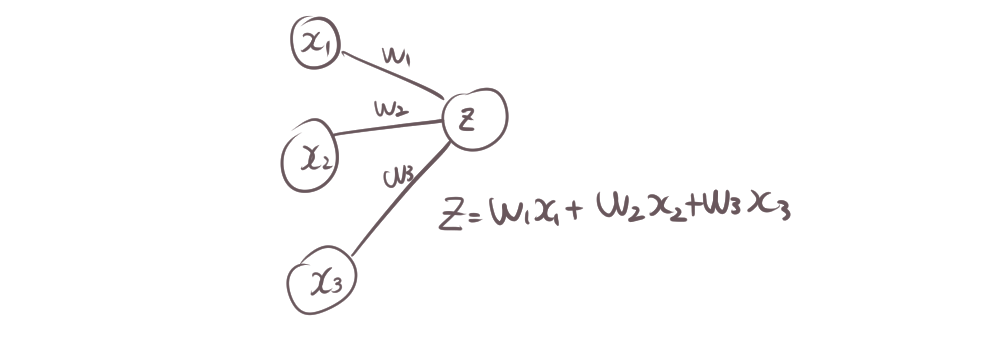
2.2. エッジ(シナプス)と重み
エッジ(またはシナプス)は、ノード間の接続を表し、ノードに信号を伝えます。各エッジには重み(ウェイト)が割り当てられ、入力信号を重み付けします。
このように、左から右に信号が伝播していくことを順伝播(Feed Foward)と呼びます。
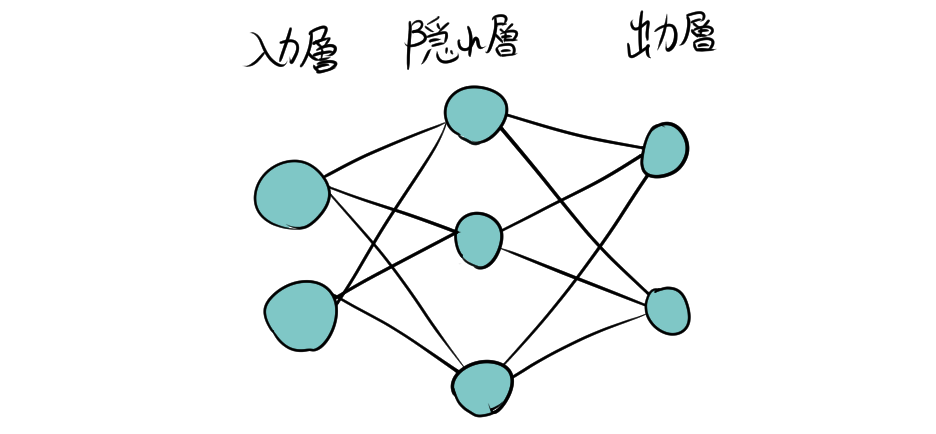
2.3. レイヤー(層)
- 入力層:データをモデルに入力する層。
- 隠れ層:入力層と出力層の間に位置し、データの特徴を抽出する層。
- 出力層:最終的な結果を出力する層。
ニューラルネットワークは、これらの層を組み合わせて構築されます。特に、隠れ層を多層に重ねたモデルはディープニューラルネットワークと呼ばれます。
3. 活性化関数
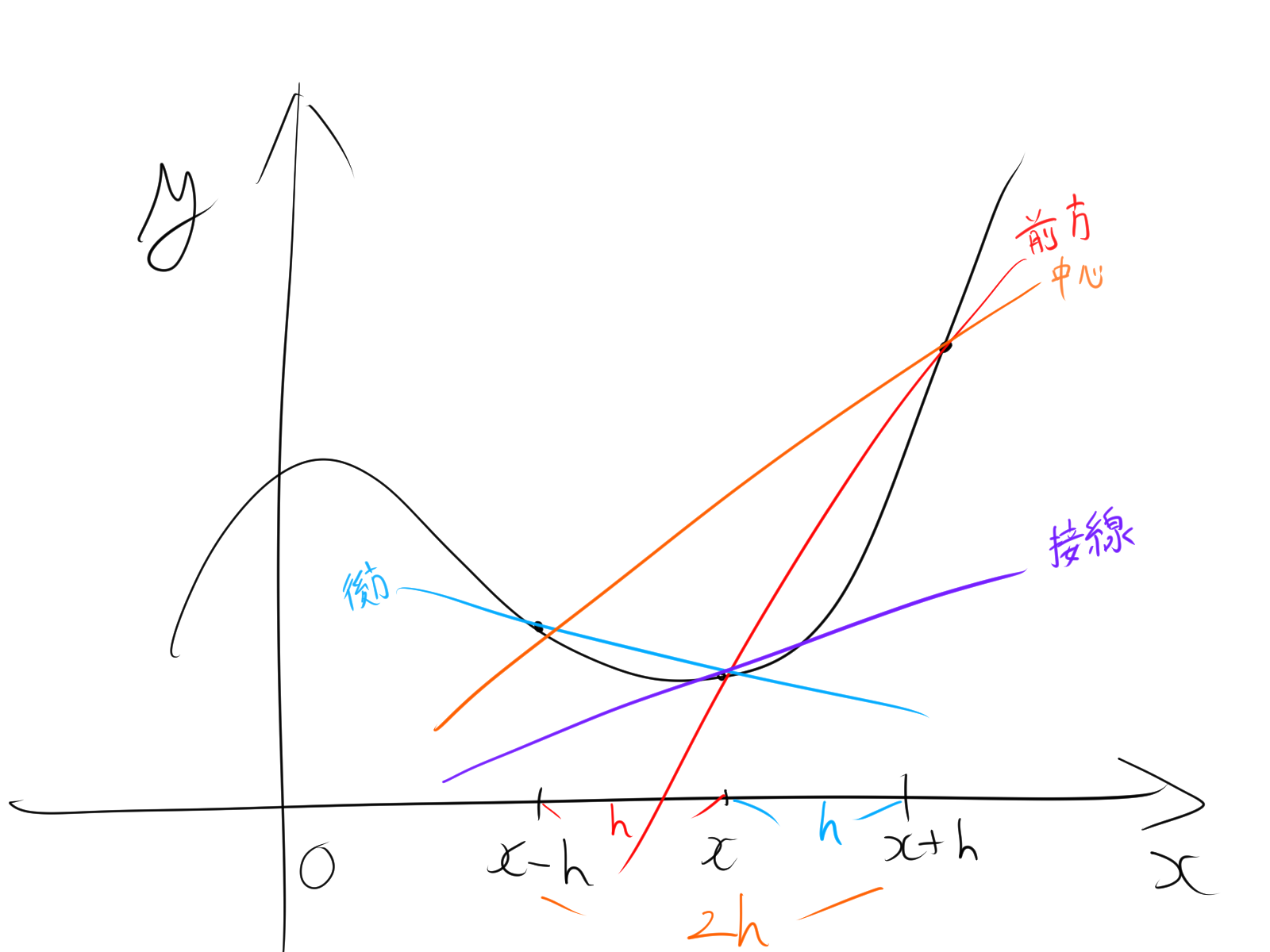
活性化関数は、ノードの出力を決定するために使用される関数です。線形な変換だけでは複雑な問題を解決できないため、非線形な活性化関数が利用されます。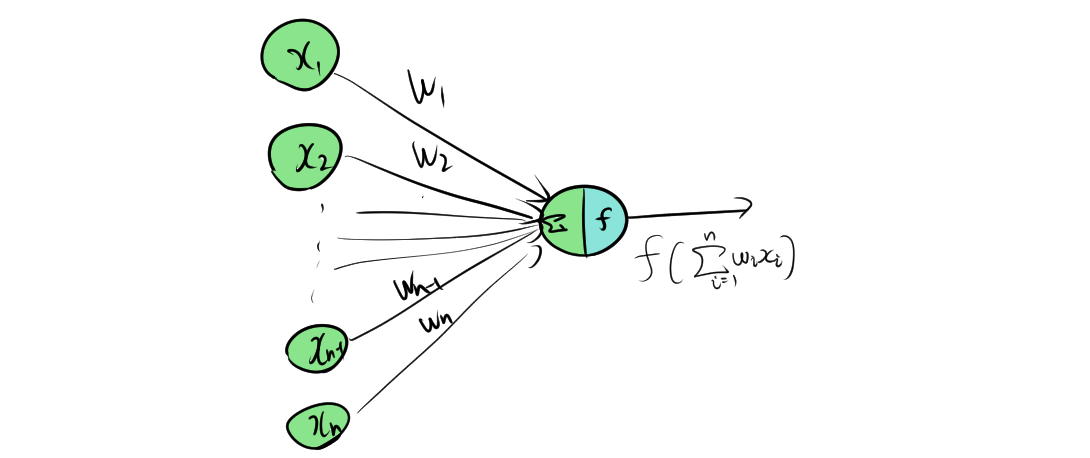
3.1. 主な活性化関数
- シグモイド関数:出力を0から1の間に収める。
- ReLU(Rectified Linear Unit):0以下の値を0、正の値はそのまま出力。
- tanh関数:出力を-1から1の間に収める。
- ソフトマックス関数:出力を確率分布に変換する。
4. 学習と訓練
4.1. 学習の流れ
- 順伝播(Feed-forward)を計算。
- 損失関数を計算
- 誤差逆伝播法で勾配を計算
- 最適化アルゴリズムを利用して重みを更新
4.2. 損失関数
損失関数は、モデルの予測結果と実際の値との誤差を計算します。損失関数を最小化することで、モデルの精度を向上させます。
- 平均二乗誤差(MSE):回帰問題でよく使用。
- クロスエントロピー損失:分類問題で使用。
4.3. バックプロパゲーション
バックプロパゲーション(誤差逆伝播法)は、誤差を出力層から入力層へ逆伝播させ、重みを更新する手法です。これにより、ネットワーク全体の学習が可能となります。
4.4. 最適化アルゴリズム
最適化アルゴリズムは、損失関数を最小化するために重みを更新します。
- 確率的勾配降下法(SGD):全データの一部を使用して重みを更新。
- Adam:学習率を適応的に調整する高度なアルゴリズム。
- RMSprop:勾配の二乗平均を利用して学習率を調整。
5. 過学習と正則化
5.1. 過学習
過学習は、モデルが訓練データに過度に適合し、新しいデータに対して性能が低下する現象です。
5.2. 正則化手法
過学習を防ぐために、正則化と呼ばれる手法が用いられます。
- ドロップアウト:ランダムにノードを無効化。
- L1・L2正則化:損失関数にペナルティ項を追加。
- 早期停止:検証データの性能が向上しなくなった時点で訓練を停止。
6. 特殊なニューラルネットワーク
6.1. 畳み込みニューラルネットワーク(CNN)
CNNは、主に画像データの処理に適したネットワークです。畳み込み層とプーリング層を組み合わせ、空間的な特徴を効果的に抽出します。
6.2. リカレントニューラルネットワーク(RNN)
RNNは、時系列データやシーケンスデータの処理に適しています。過去の情報を内部状態に保持し、連続的なデータに対処します。LSTMやGRUなどの拡張も存在します。
6.3. トランスフォーマー
トランスフォーマーは、自己注意機構(アテンション)を用いたネットワークで、自然言語処理の分野で革新的な成果を上げています。代表的なモデルにBERTやGPTシリーズがあります。