【深層学習】活性化関数Parametric ReLU (PReLU)の意味と性質について



1. Parametric ReLU (PReLU)とは?
Parametric ReLU(パラメトリックReLU、PReLU)は、活性化関数の一つです。ReLU(Rectified Linear Unit)は広く使用されている活性化関数の一つですが、PReLUはReLUの改良版となっています。PReLUは、ReLUが抱える「Dying ReLU問題」を解決するための工夫がされており、より柔軟に学習できる特性を持っています。
2. PReLUの基本的な仕組み
2.1. ReLU関数
まず、一般的なReLU関数は次のように定義されます。
この関数では、入力値 \(x\) が0より大きい場合、そのままの値を出力しますが、0以下のときは出力が常に0になります。これはシンプルで計算が効率的ですが、負の値を全て0にしてしまうため、ある層の多くのニューロンが「死んでしまう」ことが起きる可能性があります。これを「Dying ReLU問題」と言い、学習が進まなくなる場合があります。
2.2. PReLU
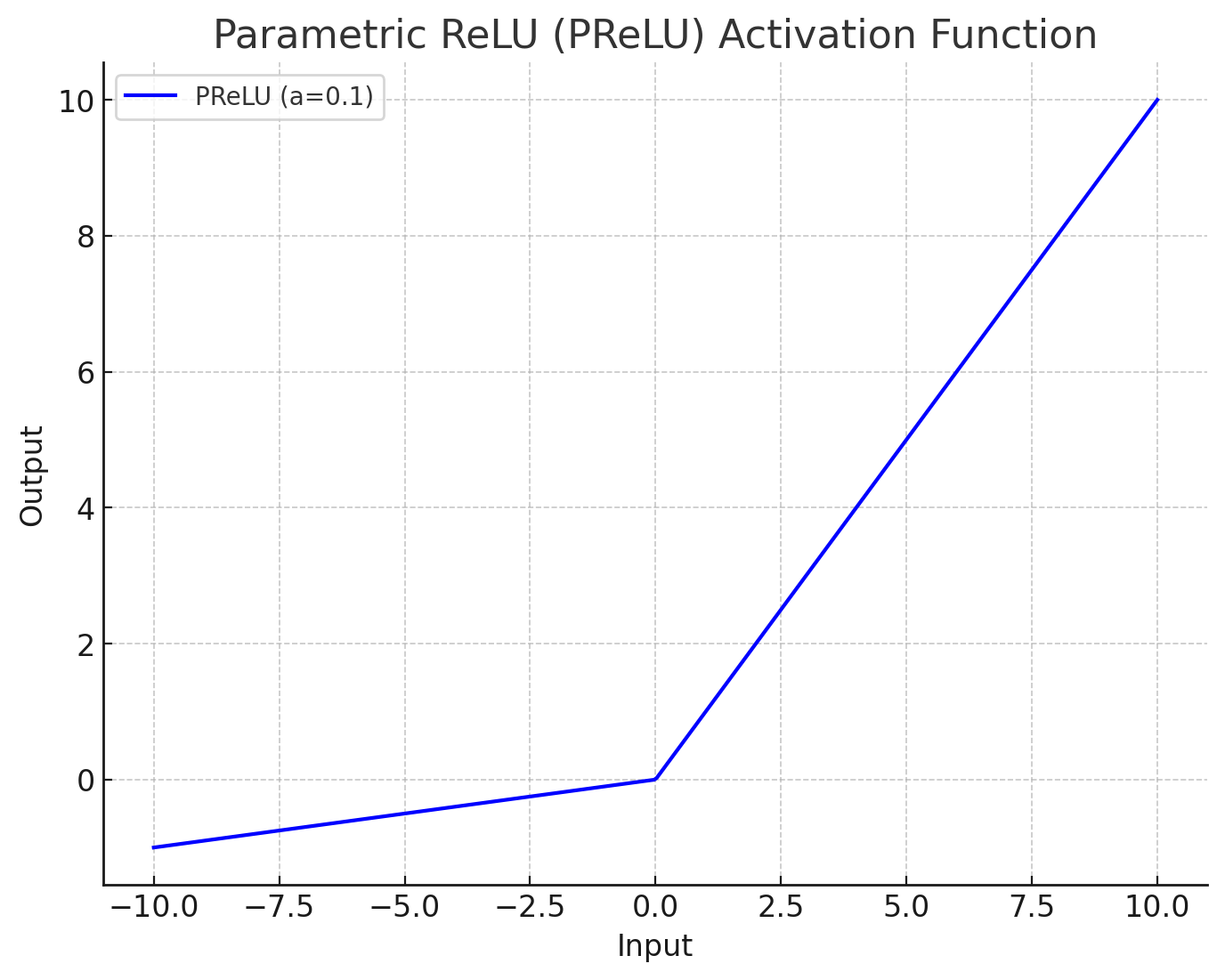
これに対し、PReLUでは、負の値に対してもある程度の出力を許容するように設計されています。PReLUの数式は以下の通りです。
ここで、\( a \) は学習可能なパラメータであり、通常は小さな値(例:0.01)で初期化されます。学習を通じてこの \( a \) の値が最適化され、モデルに最も適した負の傾きが得られます。これにより、モデルは負の値も考慮した学習が可能となり、柔軟性が増します。
論文「Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification」では、Parametric ReLU (PReLU) を活性化関数として使用することにより、ImageNet 2012分類データセットでの性能が向上することが報告されています。
3. PReLUの微分
PReLUは \( x = 0 \) の点で微分可能ではありません。しかし、ニューラルネットワークなどの応用では、実装上の単純化やアルゴリズム上の理由から、あえて「形式的に」以下のように記述します。
4. PReLUとLeaky ReLU
4.1. Leaky ReLU
Leaky ReLUはPReLUと同様にReLUの改良版として提案され、負の入力に対しても一定の傾きを持たせた活性化関数となっています。Leaky ReLUの数式は次の通りです.
ここで、\(\alpha\) は定数で固定されています。通常は小さな値(例:0.01)に設定されます。この\(\alpha\)により、負の入力でも少量の出力があり、ニューロンが「死んでしまう」ことを防ぐ設計となっています。
- \(\alpha\)は固定値:Leaky ReLUでは、この傾きの値はあらかじめ決められており、学習によって変化することはありません。多くの場合、\(\alpha = 0.01\)が使用されます。
4.2. 違い
Leaky ReLUとParametric ReLU(PReLU)はどちらも、ReLUが抱える「Dying ReLU問題」を改善するために開発された活性化関数です。ですが、PReLUは学習するパラメータがあるという点で違います。
5. 関連した記事
-
YOLOv10で鳥を見つけよう!Ultralyticsを使用した物体検出

-
ValueError: The checkpoint you are trying to load has model type `gemma2` but Transformers does not recognize this architecture.の解決方法!gemma2の読み込み
-
-
KLダイバージェンス(Kullback-Leibler Divergence)!基礎から実際の計算まで

-
scikit-learnとは?機能や使い方・できることについて解説!

-
【デコーディング手法】top_p(nuclear sampling)の意味と使い方について
