【PyTorch】MNISTを学習させて手書き文字認識、画像分類を行う方法



1. MNISTデータセットとは?
MNISTデータセットは、0から9までの手書き数字の画像を集めたデータセットで、機械学習を学ぶための教材として広く利用されています。各画像は28×28ピクセルのグレースケール画像で、データセット全体には70,000枚の画像が含まれています(学習用データ60,000枚、テスト用データ10,000枚)。このデータセットは、分類問題の理解や、ディープラーニングモデルの構築に最適です。
今回の目標は、MNISTデータセットの各数字(0から9)を1枚ずつ取り出し、モデルが予測したラベル(推測されたラベル)と、実際の正解ラベルを表示することです。正解ラベルは「True」、推測されたラベルは「Pred」として表示されます。

2. モデルの学習方法
MNISTとういう手書き数字の画像に対して学習させる方法を見ていきます。
2.1. データの準備
まずは、学習データとテストデータを準備します。PyTorchでは、torch.utils.data.Datasetとtorch.utils.data.DataLoaderを使って、MNISTのデータを取り扱うことができます。
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# データ変換(前処理)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # 平均と標準偏差で正規化
])
# 学習データセットとテストデータセットのダウンロード
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
# データローダーの作成
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
学習とテストのデータセットは、それぞれPyTorchのDataLoaderを使ってバッチ処理できるようにします。これにより、データの効率的なロードと処理が可能になります。
2.2. モデルの定義
次に、手書き数字を認識するためのモデルを定義します。今回は、シンプルなMLPを使用します。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 512) # 入力層から隠れ層
self.relu = nn.ReLU()
self.fc2 = nn.Linear(512, 10) # 隠れ層から出力層
def forward(self, x):
x = x.view(-1, 28 * 28) # 28x28の画像をフラットにする
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Net().to(device)ここでの重要なポイントは、x.view(-1, 28 * 28)で画像データの形を変換している部分です。28×28ピクセルの画像は、そのままだと行列のサイズが合わないため、フラットにする必要があります。仮にこの変換を行わなければ、行列のサイズが合わないと怒られてしまいます。
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1792×28 and 784×512)
x.view(-1, 28 * 28)の-1は自動的に次元を合わしてくれます。
2.3. 損失関数の定義
次に、損失関数を定義します。損失関数は、モデルの予測結果と正解データの差を数値化して、学習の際に使用します。分類問題においては、クロスエントロピー「nn.CrossEntropyLoss」を使います。
criterion = nn.CrossEntropyLoss()
2.4. オプティマイザの定義
オプティマイザは、損失を最小化するようにモデルのパラメータを更新する役割を果たします。今回は、確率的勾配降下法(SGD)を使い、学習率を0.01に設定しています。
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
2.5. 学習の実装
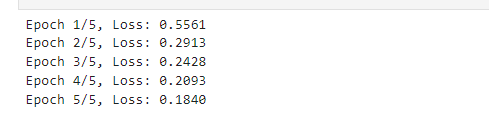
学習は、データをバッチ単位でモデルに入力し、損失を計算した後、パラメータを更新する手順を繰り返して行います。以下のコードでは、5エポックにわたってモデルを訓練しています。
epochs = 5
for epoch in range(epochs):
model.train() # 訓練モードに設定
running_loss = 0.0
for inputs, labels in train_loader:
inputs,labels = inputs.to(device),labels.to(device)
# 1. 勾配の初期化
optimizer.zero_grad()
# 2. フォワードパス
outputs = model(inputs)
# 3. 損失の計算
loss = criterion(outputs, labels)
# 4. バックワードパス(勾配計算)
loss.backward()
# 5. パラメータの更新
optimizer.step()
running_loss += loss.item()
epoch_loss = running_loss / len(train_loader)
print(f'Epoch {epoch+1}/{epochs}, Loss: {epoch_loss:.4f}')各エポックの損失が表示され、モデルが少しずつ最適化されていく様子が確認できます。
2.6. モデルの評価
学習が終了した後、テストデータを使ってモデルの性能を評価します。テストデータに対する予測の正確さと損失を計算し、モデルの精度を確認します。
model.eval() # 評価モードに設定
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')![]() 一応、95%の正解率を超えたようですね。
一応、95%の正解率を超えたようですね。
2.7. 可視化
最後に、matplotlibを利用して、最初に見せた画像のデータの可視化を行ってみましょう。argmaxを使って、一番確率の高い、ラベルを選択します。
import matplotlib.pyplot as plt
# 各数字(0〜9)の画像を1枚ずつ取得
digit_images = {}
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
for i in range(len(target)):
label = target[i].item()
if label not in digit_images:
digit_images[label] = (data[i], target[i])
if len(digit_images) == 10:
break
if len(digit_images) == 10:
break
# プロットの準備
fig, axes = plt.subplots(2, 5, figsize=(12, 5))
axes = axes.flatten()
# 各数字の画像を表示
for idx in range(10):
data, target = digit_images[idx]
data, target = data.unsqueeze(0), target.unsqueeze(0)
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
pred_label = pred.item()
true_label = target.item()
# 画像をCPUに移して表示
image = data.cpu().squeeze().numpy()
axes[idx].imshow(image, cmap='gray')
axes[idx].axis('off')
# タイトルの設定
if pred_label == true_label:
color = 'red'
else:
color = 'blue'
axes[idx].set_title(f'True: {true_label}, Pred: {pred_label}', color=color)
plt.tight_layout()
plt.show()これで、各数字ごとの画像と、その正解ラベルおよび予測ラベルを確認できます。正確な予測が行われた場合はタイトルが赤色で表示され、間違っている場合は青色になります。
3. ポイント
3.1. 初期化の注意
super().__init__()は必ず呼び出してください。これにより、親クラスnn.Moduleの初期化処理が行われます。
3.2. 学習率の調整
学習率はモデルの収束に大きな影響を与えます。適切な値を選びましょう。
3.3. チェックポイントの保存
学習の途中でモデルを保存することで、途中から再開できます。
# チェックポイントの保存
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, 'checkpoint.pth')
# チェックポイントの読み込み
checkpoint = torch.load('checkpoint.pth')
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch']