【深層学習】ReLU(Rectified Linear Unit、ランプ関数)の意味と性質について



1. ReLU(Rectified Linear Unit)とは
1.1. 定義
\[ f(x) = \max(0, x) \]
これは
- x < 0 の場合:\(f(x) = 0\)
- x >= 0 の場合:\(f(x) = x\)
を意味します。これは、次のようにも表すことができます。
また、絶対値を利用して次のように表すことができます。
このように、ReLUは負の入力をゼロにし、正の入力はそのまま通すという動作をします。ランプ関数とReLU(Rectified Linear Unit)は数学的に同じであり、負の入力をゼロにし、正の入力をそのまま通します。
1.2. 名称
ReLUは「Rectified Linear Unit」の略称で次のように呼ばれることがあります。
- ランプ関数
- 正規化線形関数
1.3. 用途
ReLUはディープラーニングのニューラルネットワークで主に使用され、各層の出力を調整する「活性化関数」として働きます。特に、ReLUの特徴は「勾配消失問題(gradient vanishing problem)」と呼ばれる問題を回避しやすいことです。ニューラルネットワークの学習で、負の入力をゼロにし、正の入力のみを通すことで、信号を次の層に適切に伝えやすくします。
2. グラフでのイメージ
ReLU(Rectified Linear Unit)のグラフは、x軸の負の部分では常にゼロの高さにあり、x軸の正の部分では45度の直線として上昇します。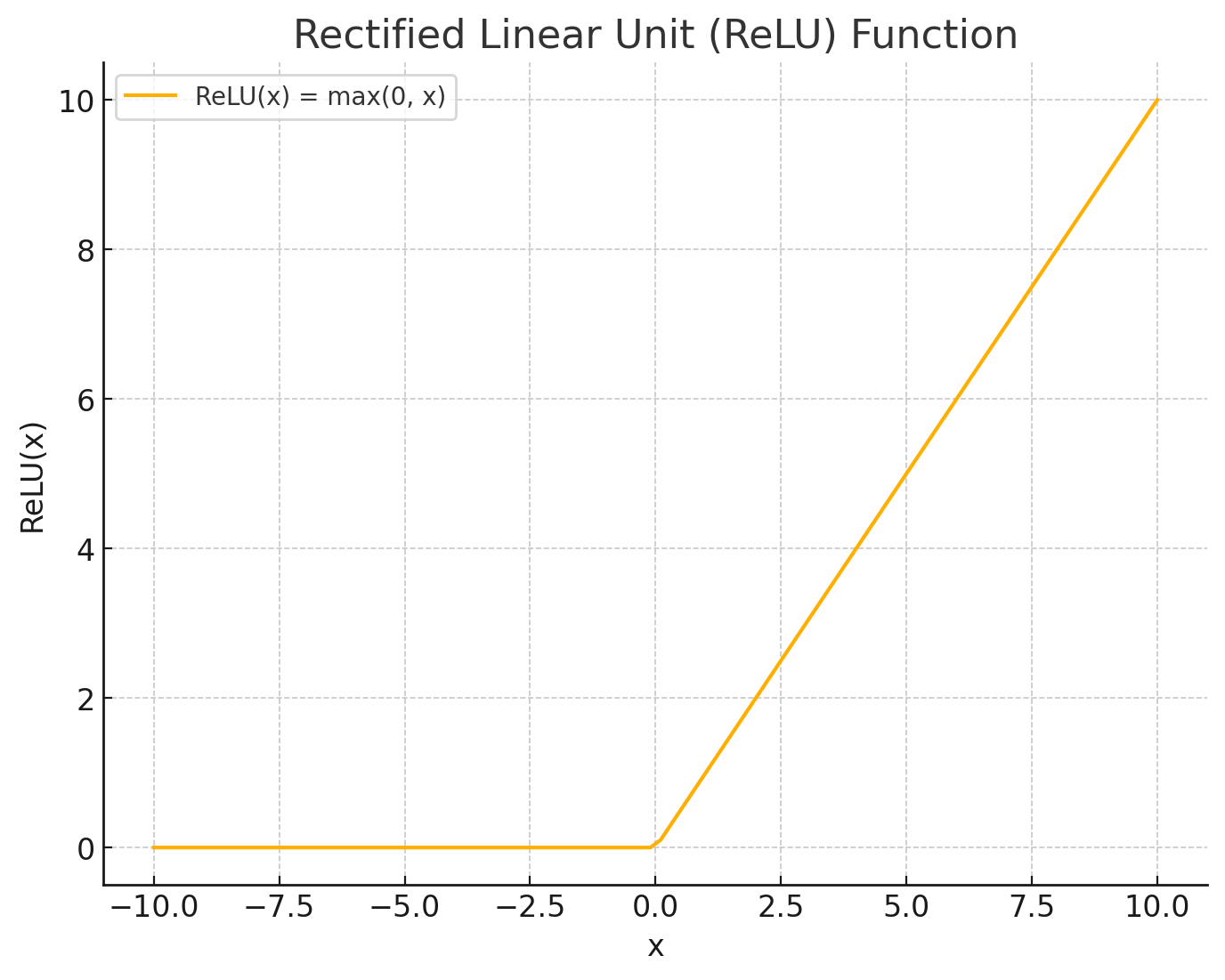
- x ≤ 0:出力は常に0になります。したがって、グラフはx軸上に水平な線として描かれます。
- x > 0:出力はxの値と等しいので、グラフは45度の直線(y = x)として描かれます。
3. ReLU関数の微分
\[ f'(x) = \begin{cases} 0 & (x < 0) \\ 1 & ( x \geq 0) \end{cases} \]
4. ReLUの派生
ReLU(Rectified Linear Unit)は、ニューラルネットワークで広く使われている活性化関数で、その派生としていくつかの重要なバリエーションが提案されています。
4.1. Leaky ReLU(リーキーReLU)
Leaky ReLUは、ReLUが持つ「ニューロンが死んでしまう」という問題に対処するために開発されました。通常のReLUでは、入力が負の値になると出力がゼロになり、これが原因で「ニューロンが死んでしまう」問題が生じることがあります。Leaky ReLUは、負の入力に対して小さな傾きを持たせ、少しだけ負の出力を許容します。数式で表すと以下のようになります。
ここで、\(\alpha\) は小さな正の定数(通常0.01)です。
4.2. Exponential Linear Unit(ELU, 指数線形単位)
ELUは、ReLUのような非線形性を保ちながらも、負の値の出力に対して指数関数を用いていて、勾配消失問題を軽減します。学習が安定しやすくなり、画像分類のタスクではReLUよりも高い精度が期待できる場合があります。数式で表すと以下のようになります。




