更新:2024/09/17
scikit-learnのデータセットの読み込みの使い方!sklearn.datasetsについて


ふゅか
scikit-learnって、色々なデータセットが使えるから便利だよね!まずは基本的なところから始めましょう♪

はるか
そうだね。まずはデータセットの種類から。
目次
1. scikit-learnのデータセット
scikit-learnでは、機械学習の学習や実験に使用するためのさまざまなデータセットを提供しています。これらのデータセットは、データの分析やモデルの練習に便利です。
1.1. データセットの種類
scikit-learnで利用できるデータセットには、以下のような種類があります。
- toyデータセット: 小規模で簡単に扱えるデータセット(例: Iris、Wine、Breast Cancer)
- 実世界のデータセット: 比較的大規模で実際のデータに基づくもの(例: Boston Housing、Diabetes)
- 外部データセット: 外部ファイル(CSV、Excelなど)から読み込むデータ
ふゅか
scikit-learnにはtoyデータセット、実世界のデータセット、それに外部データセット!toyデータセットは、IrisやWineなどの小規模で簡単なデータが入っているの。
はるか
うん、簡単に試すのに使いやすい。
2. データセットの読み込み
データセットを読み込むためには、sklearn.datasetsモジュールを使用します。以下に、いくつかの例を示します。
2.1. toyデータセットの読み込み
Irisデータセットを読み込む例。
from sklearn.datasets import load_iris
# データセットの読み込み
iris = load_iris()
# データの確認
X = iris.data # 特徴量
y = iris.target # ターゲットラベル
2.2. 実世界のデータセットの読み込み
California Housingデータセットを読み込む例。
from sklearn.datasets import fetch_california_housing
# データセットの読み込み
california = fetch_california_housing()
# データの確認
X = california.data # 特徴量
y = california.target # ターゲットラベル
2.3. 外部データセットの読み込み
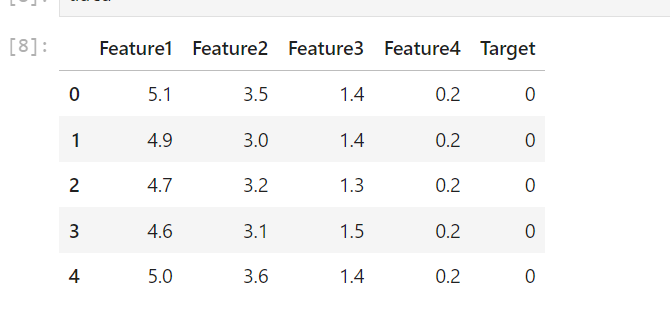
CSVファイルなどの外部データを読み込む場合には、pandasを使用すると便利です。実験用データセットをpandasを使ってをCSVファイルに作成します。
import pandas as pd
# 実験用データセットを作成
data = {
'Feature1': [5.1, 4.9, 4.7, 4.6, 5.0],
'Feature2': [3.5, 3.0, 3.2, 3.1, 3.6],
'Feature3': [1.4, 1.4, 1.3, 1.5, 1.4],
'Feature4': [0.2, 0.2, 0.2, 0.2, 0.2],
'Target': [0, 0, 0, 0, 0]
}
# DataFrameを作成
df = pd.DataFrame(data)
# CSVファイルに保存
csv_file_path = 'experiment_data.csv'
df.to_csv(csv_file_path, index=False)実験用データセットを読み込みます。
import pandas as pd
csv_file_path = 'experiment_data.csv'
# CSVファイルの読み込み
data = pd.read_csv(csv_file_path)
# 特徴量とターゲットの分離
X = data.drop('Target', axis=1) # 特徴量
y = data['Target'] # ターゲットラベルdataは次のようになっています。
PR