【scikit-learn】決定木による分類の意味と使い方について



1. 決定木
決定木(Decision Tree)は、データを使った分類や回帰の問題を解くために使われる、非常にシンプルで分かりやすい機械学習アルゴリズムの一つです。Scikit-learnはPythonで機械学習ライブラリで、決定木を簡単に実装するための便利なツールを提供しています。この記事では、決定木の基本的な仕組みと、scikit-learnを使った決定木による分類の実装方法をわかりやすく解説します。
2. 木構造
決定木は、木構造を利用してデータを分割していくアルゴリズムです。この木構造には、主に以下の3つの要素があります。
- ルートノード
- 内部ノード
- 葉ノード
2.1. ルートノード
木の一番上に位置するノードで、最初のデータ分割が行われます。
2.2. 内部ノード
データがさらに分割される場所。特徴量(データの属性)を基に条件分岐します。
2.3. 葉ノード
分割が終わり、最終的な分類や予測値を示すノード。
3. 分割基準
決定木の分割基準とは、データを最適に分類するための基準で、以下の2つの指標が代表的です。
- ジニ不純度
- エントロピー(情報利得)
4. Scikit-learnでの決定木の実装
Scikit-learnでは、DecisionTreeClassifier(分類用)やDecisionTreeRegressor(回帰用)を使って簡単に決定木を実装できます。今回の場合は、アヤメの品種の分類を行うので、分類木を使用します。
4.1. 必要なライブラリをインポート
まず、必要なライブラリをインポートします。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
4.2. データセットの準備
Scikit-learnのload_iris関数を使って、データセットをロードします。
# データセットのロード
data = load_iris()
X = data.data # 特徴量
y = data.target # ラベル
# データを訓練用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.6, random_state=42)
4.3. 決定木モデルの作成
データの準備が整ったら、DecisionTreeClassifierを使って決定木モデルを作成し、訓練データで学習させます。
# 決定木モデルのインスタンス化
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42)
# モデルの訓練
clf.fit(X_train, y_train)
criterion='gini':ジニ不純度を使用。max_depth=3:木の深さを3に制限して過学習を防止。
4.4. モデルの評価
テストデータで予測を行い、精度を確認します。
# テストデータで予測
y_pred = clf.predict(X_test)
# 精度の計算
accuracy = accuracy_score(y_test, y_pred)
print(f"モデルの精度: {accuracy * 100:.2f}%")

4.5. 決定木の可視化
Scikit-learnでは、plot_treeを使って決定木を可視化できます。
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 決定木の可視化
plt.figure(figsize=(12, 8))
plot_tree(clf, feature_names=data.feature_names, class_names=data.target_names, filled=True)
plt.show()
実際に動かすと次のようになります。
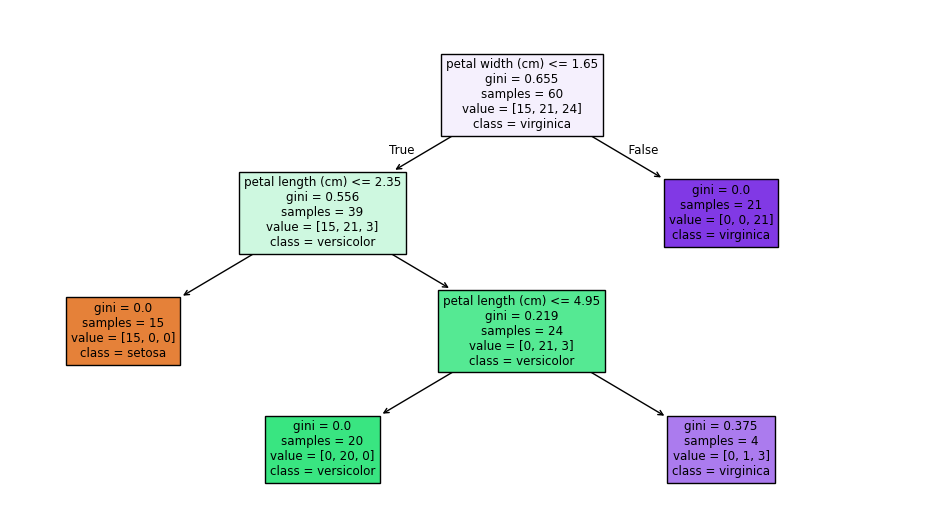
この図を見れば、データがどの特徴量(例:花びらの長さや幅)を基に分類されているのかが一目でわかります。例えば、ルートノード(最上位)では、花びらの幅でデータが分割されています。
5. 決定木のハイパーパラメータ
決定木にはいくつかの重要なハイパーパラメータがあります。以下はよく使われるものです。
criterion: 分割基準(giniまたはentropy)。max_depth: 木の最大深さ。min_samples_split: 内部ノードを分割するために必要な最小サンプル数。min_samples_leaf: 葉ノードに必要な最小サンプル数。



