更新:2024/09/30
scikit-learnのインストールと基本的な使い方!学習と予測について


はるか
scikit-learnのインストールって、すぐできるの?

ふゅか
うん!「pip install scikit-learn」ってコマンドを使うだけで、簡単にインストールできるよ。Pythonがちゃんと動いてれば問題ないわ!
目次
1. scikit-learnのインストール
scikit-learnはPythonの機械学習ライブラリで、様々なアルゴリズムが簡単に利用できます。まず、scikit-learnをインストールしましょう。
pip install scikit-learn
2. scikit-learnの基本的な使い方
Scikit-learnの使い方は、データの前処理、モデルの選択、学習、予測という一連の流れで進みます。以下は、Scikit-learnを使った基本的な手順です。
ふゅか
まず、データを準備するところから始めるわ。Scikit-learnにはirisデータセットが組み込まれているから、それを使ってみるね。
はるか
irisって、アヤメのこと?
ふゅか
そうそう!このデータセットには、がく片と花弁の長さや幅が含まれているの。それでアヤメ属の3種類を識別できるんだ。
2.1. データの準備
まず、データセットを用意します。Scikit-learnにはいくつかのデータセットが組み込まれているので、それを利用できます。例えば、iris(あやめ)データセットを使います。
from sklearn.datasets import load_iris
import numpy as np
# データセットの読み込み
iris = load_iris()
X = iris.data # 特徴量
y = iris.target # ラベル
irisのデータセットの特徴量は次のようになってます。
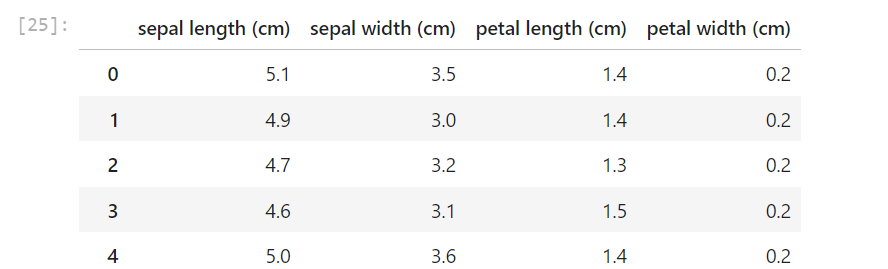
Irisの特徴量は以下の4つです。
- sepal length (cm) – がく片の長さ(センチメートル)
- sepal width (cm) – がく片の幅(センチメートル)
- petal length (cm) – 花弁の長さ(センチメートル)
- petal width (cm) – 花弁の幅(センチメートル)
これらの特徴量は、アヤメ属の3種類(Setosa、Versicolor、Virginica)を識別するために使用されます。
2.2. トレーニングデータとテストデータの分割
データをトレーニングデータとテストデータに分割します。train_test_splitを使用して分割します。
from sklearn.model_selection import train_test_split
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
2.3. モデルの選択と学習
ふゅか
次に、モデルを選択して学習させるよ。例えば、決定木分類器を使ってみるね。
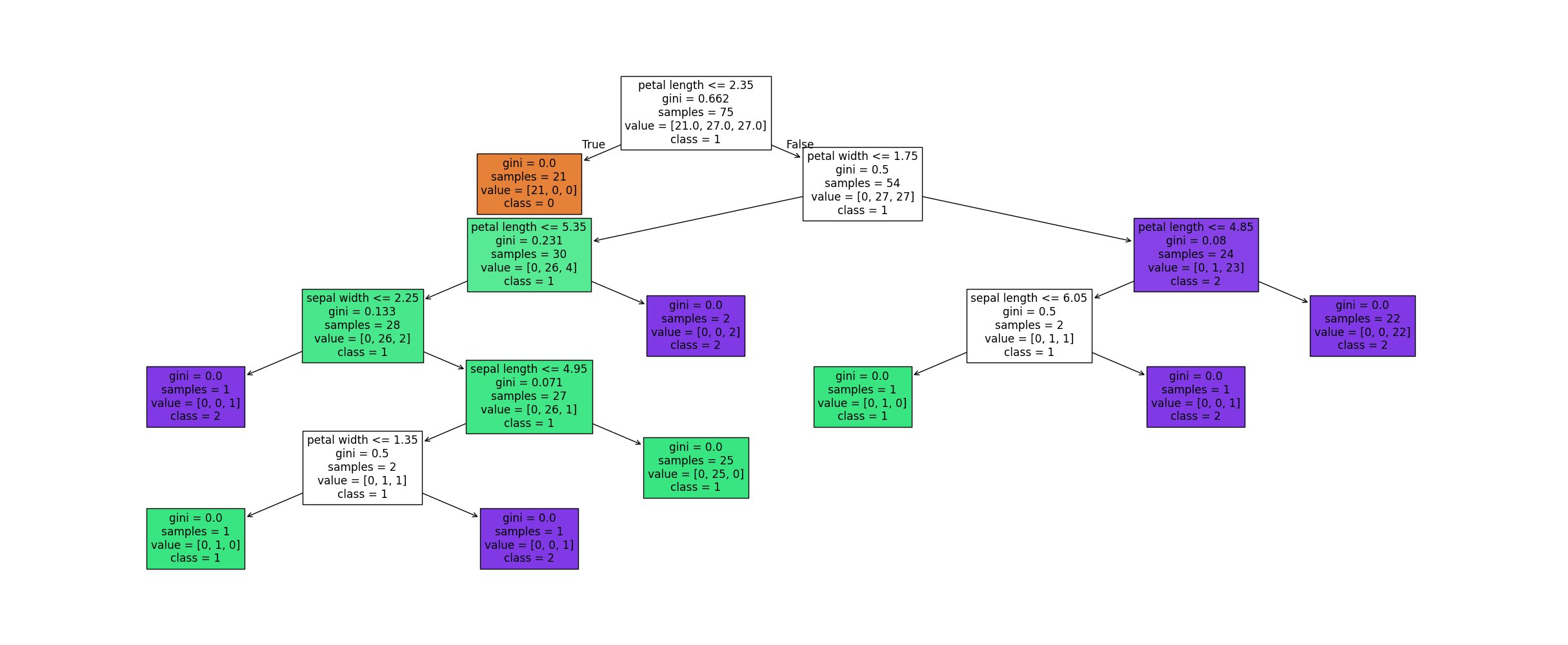
次に、使用するモデルを選択し、トレーニングデータで学習させます。ここでは、決定木分類器を例にします。
from sklearn.tree import DecisionTreeClassifier
# モデルの選択
model = DecisionTreeClassifier()
# モデルの学習
model.fit(X_train, y_train)
2.4. 予測と評価
テストデータを使ってモデルの予測を行い、その性能を評価します。
from sklearn.metrics import accuracy_score
# 予測
y_pred = model.predict(X_test)
# モデルの評価
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
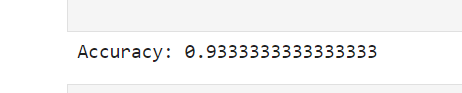
これで、基本的なScikit-learnの使い方がわかりました。この流れを応用して、他のアルゴリズムやデータセットを使用することができます。
PR




