更新:2024/12/08
【scikit-learn】ランダムフォレストの意味と使い方について


はるか
ランダムフォレスト。アンサンブル学習の一種。

ふゅか
ランダムフォレストって、複数の決定木を組み合わせて予測する手法だよね!分類も回帰もできるんだって!
目次
1. ランダムフォレストとは?
ランダムフォレスト(Random Forest)は、機械学習で使われるアンサンブル学習の手法の一つで、多数の決定木(Decision Trees)を組み合わせて予測を行うアルゴリズムです。分類問題や回帰問題のどちらにも対応しており、決定木を単体で使うよりも、高い精度と汎化性能(未知のデータに対する適応力)を持つのが特徴です。
2. ランダムフォレストの仕組み
ランダムフォレストは、以下のステップでモデルを構築し、予測を行います。
2.1. データのランダムなサンプリング
データセットからランダムにサンプルを選び出して複数のサブセットを作成します。同じデータが複数回選ばれる可能性があり、これをブートストラップサンプリングと呼びます。
2.2. 複数の決定木の作成
それぞれのサブセットを使って、決定木を構築します。ただし、決定木を作る際には、すべての特徴量を使わず、ランダムに選ばれた一部の特徴量のみを使用します。このランダム性が、複数の決定木間での多様性を生み出します。
はるか
各サブセットで決定木作成。一部特徴量だけ使用。
ふゅか
その特徴量をランダムに選ぶから、決定木ごとに多様性が生まれるんだね!これがポイントだよね!
2.3. アンサンブル(多数決または平均)
- 分類問題の場合:各決定木の予測結果を多数決で集計し、最も多く選ばれたクラスを最終的な予測結果とします。
- 回帰問題の場合:各決定木の予測値を平均して最終的な予測値とします。
3. scikit-learnでの実装方法
Pythonの機械学習ライブラリであるscikit-learnを使うと、ランダムフォレストは非常に簡単に実装できます。以下に具体的なコード例を示します。
3.1. ランダムフォレストを使った分類モデルの例
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データの読み込み
data = load_iris()
X = data.data # 特徴量
y = data.target # ラベル
# 訓練データとテストデータの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ランダムフォレストモデルの作成
model = RandomForestClassifier(n_estimators=100, random_state=42) # 100本の木を使用
model.fit(X_train, y_train) # モデルの学習
# テストデータでの予測
y_pred = model.predict(X_test)
# 精度の計算
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
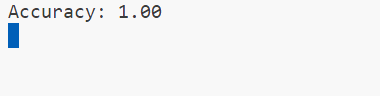
3.2. コードの説明
- データの読み込み
load_irisは、scikit-learnに付属しているtoyデータセット(アヤメのデータ)を読み込む関数です。 - データ分割
データを80%(訓練用)と20%(テスト用)に分割しています。 - モデルの作成
RandomForestClassifierを用いてランダムフォレストを構築します。n_estimators=100は、100本の決定木を使用する設定です。 - モデルの学習
fitメソッドを用いてモデルを学習させます。 - 予測と評価
テストデータで予測し、精度(Accuracy)を計算しています。
3.3. ランダムフォレストのパラメータ
ランダムフォレストには多くのパラメータがあり、それぞれの設定によって性能が変わります。主なパラメータを以下にまとめます。
| パラメータ | 説明 | デフォルト値 |
|---|---|---|
n_estimators |
使用する決定木の本数 | 100 |
max_depth |
各決定木の最大深さ | None(制限なし) |
min_samples_split |
ノードを分割するために必要な最小サンプル数 | 2 |
min_samples_leaf |
葉(Leaf)ノードに必要な最小サンプル数 | 1 |
max_features |
各決定木で使用する特徴量の最大数 | “sqrt” |
random_state |
乱数シード(再現性の確保に使用) | None |
3.4. ランダムフォレストのメリット
- 高い汎化性能 過学習(訓練データに特化しすぎる問題)を抑えられます。
- 多様な問題に対応 分類問題と回帰問題の両方に対応可能です。
- 特徴量の重要度が分かる 各特徴量の寄与度を確認することができます。
3.5. 特徴量の重要度を確認するコード例
import matplotlib.pyplot as plt
# 特徴量の重要度を取得
feature_importances = model.feature_importances_
# 可視化
plt.bar(data.feature_names, feature_importances)
plt.title("Feature Importances")
plt.xlabel("Features")
plt.ylabel("Importance")
plt.show()
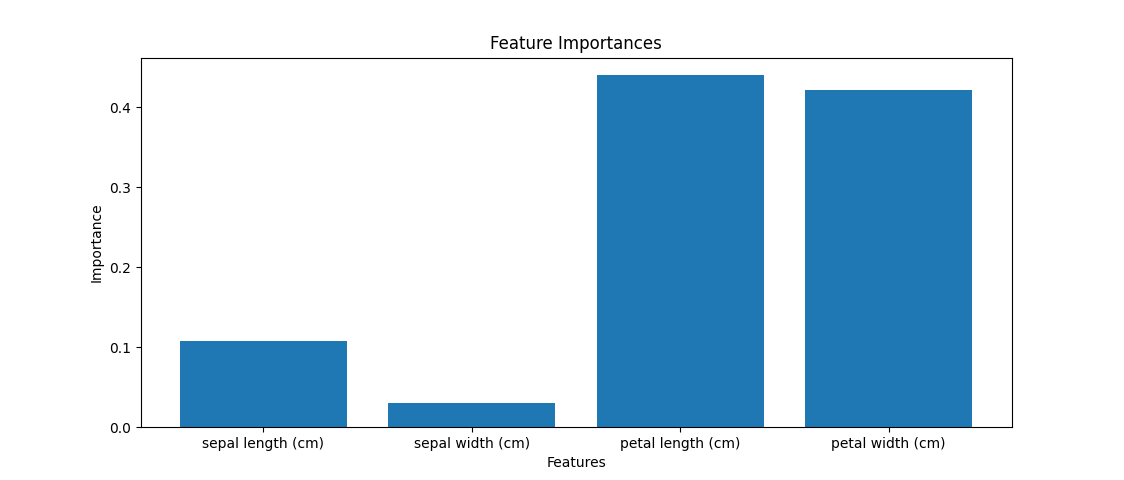
このことからpetal widthとpetal lengthがほかの二つよりも重要な特徴量であることがわかります。
PR




