更新:2024/12/06
【scikit-learn】サポートベクターマシン(SVM)の使い方と意味について


はるか
SVMか…境界をうまく引いて分類するやつ。

ふゅか
そうそう!特にScikit-learnを使うと、簡単に実装できるから便利ね!
目次
1. scikit-learnによるサポートベクターマシン
サポートベクターマシン(Support Vector Machine、以下SVM)は、機械学習のアルゴリズムの1つです。特に分類や回帰問題に適しており、シンプルなデータセットから複雑な非線形問題まで幅広く対応できます。この記事では、Scikit-learnを使ってSVMを実装する方法とその基本的な仕組みについてわかりやすく解説します。
1.1. SVMの基本的な仕組み
SVMの目的は、データを最適に分類するための境界線(超平面)を見つけることです。この境界線を見つける際、以下のような特徴を持っています:
- 最大マージン分類
データポイントから境界線までの距離(マージン)を最大化するように超平面を決定します。 - サポートベクター
境界線に最も近いデータポイントが「サポートベクター」と呼ばれます。これらのポイントが境界線の位置を決定します。 - カーネル法
線形分離が難しい場合、データを高次元空間に写像して非線形の問題を解決します。これを「カーネル法」と呼びます。
ふゅか
SVMの「超平面」って何だかわかる?
はるか
うん。データを分けるための境界線。最適なやつを探す。
2. Scikit-learnでのSVMの使い方
Scikit-learnは、Pythonで機械学習を行う際に広く使われるライブラリです。SVMを扱うためのモジュールが用意されており、簡単に実装できます。
2.1. 必要なライブラリをインポート
まず、必要なライブラリをインポートします。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
datasets: データセットの読み込みに使用します。train_test_split: データをトレーニング用とテスト用に分割します。SVC: SVMモデルを定義します。accuracy_score: モデルの精度を評価します。
2.2. データセットの準備
Scikit-learnには有名な「Irisデータセット」が含まれています。このデータを使ってSVMを訓練します。
# Irisデータセットをロード
iris = datasets.load_iris()
# 特徴量とラベルを取得
X = iris.data
y = iris.target
# データをトレーニング用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
2.3. モデルの定義とトレーニング
ここでは、SVC(サポートベクター分類器)を使用します。kernelパラメータを使ってカーネルの種類を選択できます。
# SVMモデルの作成(RBFカーネルを使用)
model = SVC(kernel='rbf', C=1.0, gamma='scale')
# モデルの訓練
model.fit(X_train, y_train)
kernel: カーネルの種類を指定します。一般的に使用されるものにはlinear(線形)、poly(多項式)、rbf(RBFカーネル)が含まれます。C: マージンを調整する正則化パラメータです。値が大きいほど過学習しやすくなります。gamma: カーネル関数の影響範囲を指定します。
2.4. モデルの評価
テストデータを使ってモデルの性能を評価します。
# テストデータで予測
y_pred = model.predict(X_test)
# 精度を計算
accuracy = accuracy_score(y_test, y_pred)
print(f"モデルの精度: {accuracy:.2f}")

2.5. カーネルの種類と特徴
SVMで使用できるカーネルには以下のような種類があります。
- 線形カーネル(linear)
データが線形に分離可能な場合に使用します。 - 多項式カーネル(poly)
非線形なデータに適しています。多項式の次数を調整可能です。 - RBFカーネル(rbf)
最も一般的に使われる非線形カーネルです。データを高次元空間に写像します。 - シグモイドカーネル(sigmoid)
ニューラルネットワークの活性化関数としても知られるシグモイド関数を利用します。
3. 境界のプロット
SVMモデルを構築し、各特徴量の組み合わせごとに境界を描画しました。以下はその結果です。
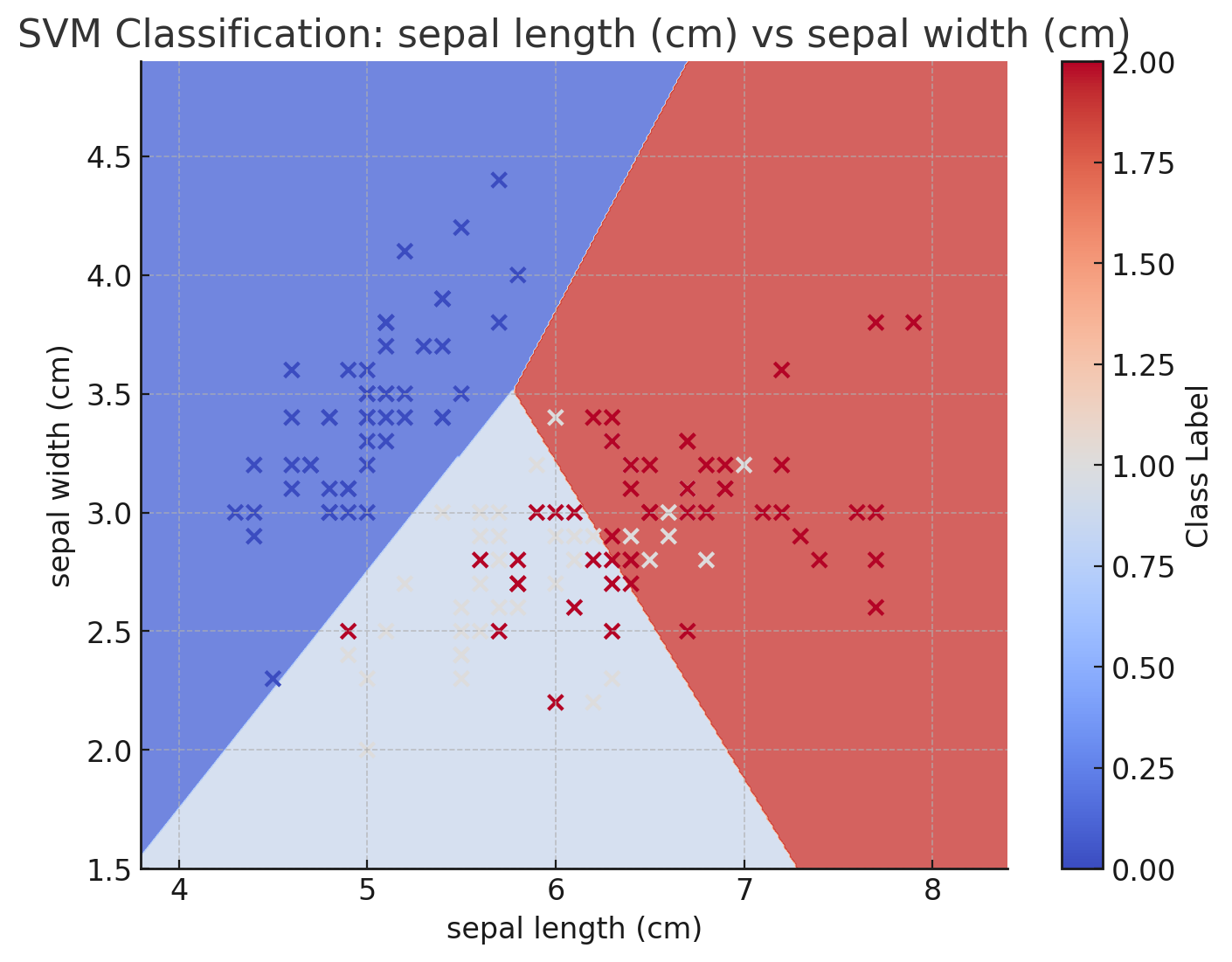
3.1. がく片の長さ vs がく片の幅
- 横軸:がく片の長さ (sepal length)
- 縦軸:がく片の幅 (sepal width)
このグラフは、がく片の長さと幅の2つの特徴量のみを使用して分類境界を描画したものです。
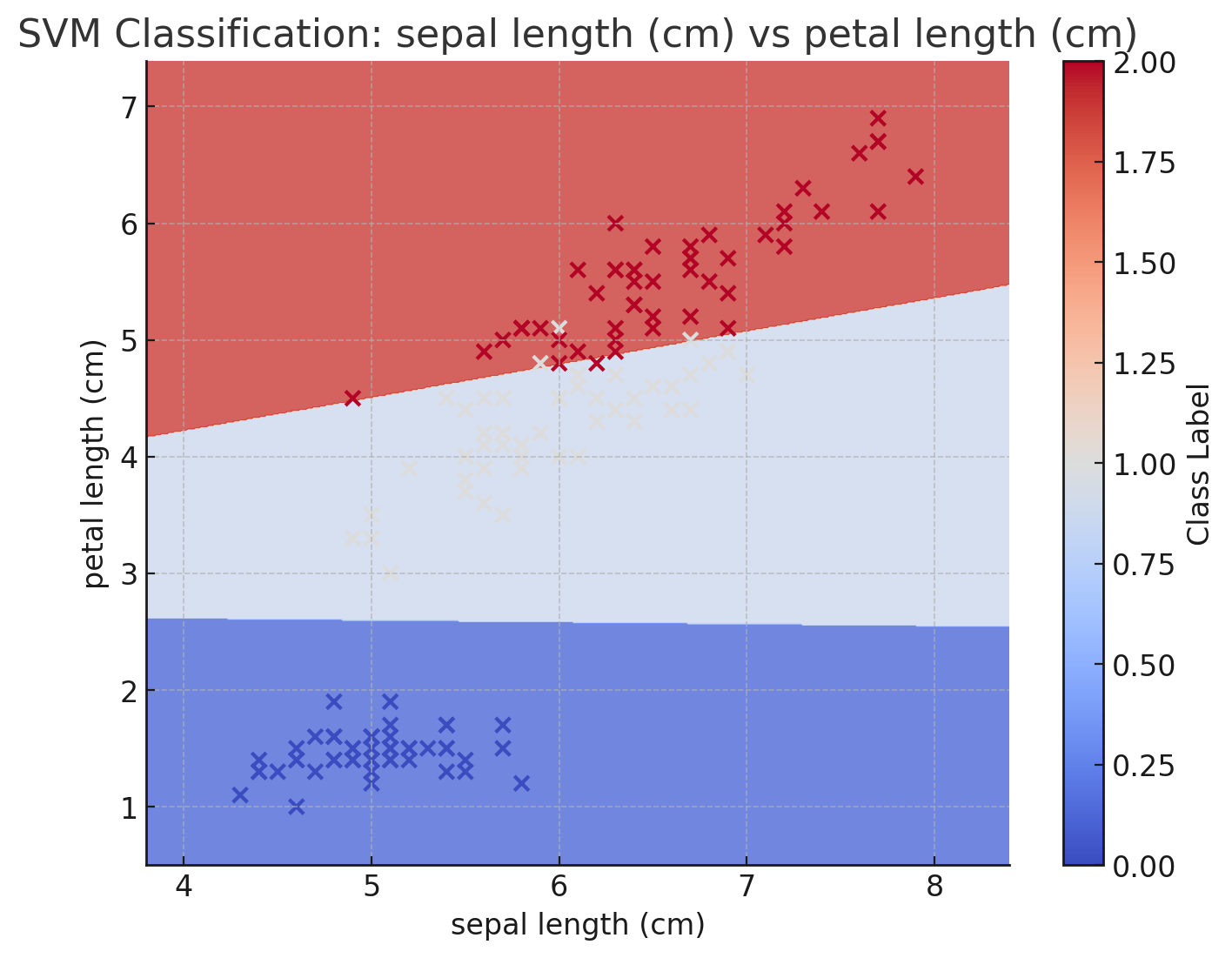
3.2. がく片の長さ vs 花びらの長さ
- 横軸:がく片の長さ (sepal length)
- 縦軸:花びらの長さ (petal length)
このグラフでは、がく片の長さと花びらの長さの組み合わせに基づいて分類境界が示されています。
4. パラメータの調整(ハイパーパラメータチューニング)
SVMの性能を最大化するためには、パラメータを調整する必要があります。以下はよく調整されるパラメータです。
- C: 過学習と汎化性能のバランスを調整。
- gamma: RBFカーネルの影響範囲を制御。
- kernel: 問題に適したカーネルを選択。
ふゅか
Cとgammaって何のためにあるか知ってる?
はるか
Cはマージンの調整。gammaはカーネルの影響範囲。
Scikit-learnでは、GridSearchCVを使用してパラメータを自動調整できます。
from sklearn.model_selection import GridSearchCV
# パラメータの設定
param_grid = {
'C': [0.1, 1, 10],
'gamma': [1, 0.1, 0.01],
'kernel': ['rbf']
}
# グリッドサーチ
grid = GridSearchCV(SVC(), param_grid, refit=True, verbose=2)
grid.fit(X_train, y_train)
# 最適なパラメータの表示
print(grid.best_params_)
PR