【深層学習】単純パーセプトロンの意味と学習について



1. 単純パーセプトロンとは?
単純パーセプトロン(Simple Perceptron)は、人工知能や機械学習において、分類問題のために提唱されたアルゴリズムの一つです。特に、二つのクラス(例:0と1やYesとNo)にデータを分けるために使用される分類器です。
2. 単純パーセプトロンの仕組み
パーセプトロンは、人間の脳の神経細胞(ニューロン)を模したモデルで、入力データに対して重みを適用し、その結果を使ってデータを分類します。以下はその基本的な流れです。
- 入力層:パーセプトロンには、複数の入力(特徴量)が入ります。
- 重み:各入力には「重み」という数値が割り当てられます。
- バイアス:パーセプトロンには「バイアス」という定数も加えられます。
- 活性化関数:入力と重みを掛け合わせた合計にバイアスを加えた値を、ある基準に従って出力を決定します。単純パーセプトロンの場合、よく用いられる活性化関数は「ステップ関数」で、合計がある閾値を超えると1、そうでない場合は0と出力します。
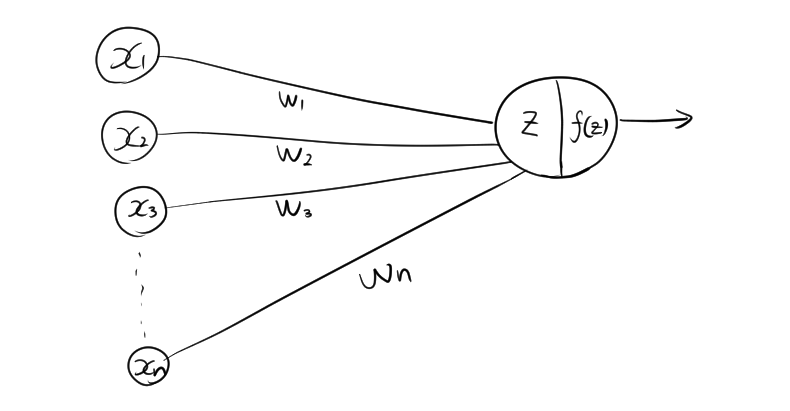
2.1. 線形結合
単純パーセプトロンでは、まず入力データとそれに対応する重みを掛け合わせ、その合計を計算します。この線形結合の式は以下のように表されます。
- \( x_1, x_2, \dots, x_n \) : 入力値(特徴量)
- \( w_1, w_2, \dots, w_n \) : 各入力に対する重み
- \( b \) : バイアス項
- \( z \) : 線形結合の結果
この式は、すべての入力と重みの積の合計にバイアスを加えたものです。
2.2. 活性化関数
活性化関数として「ステップ関数」を用いると
- \( y \) : パーセプトロンの最終出力
2.3. 全体の式
これらを組み合わせた単純パーセプトロンの出力は、以下のように表せます。
\[ y = \begin{cases} 1 & \left( \displaystyle\sum_{i=1}^{n} w_i x_i + b \geq 0 \right) \\ 0 & \left( \displaystyle\sum_{i=1}^{n} w_i x_i + b < 0 \right) \end{cases} \]
この数式によって、単純パーセプトロンは入力データが閾値を超えているかどうかに基づいて、1か0を出力する二値分類を行います。
3. パーセプトロンの学習
3.1. 重みの更新式
\[ w_i \leftarrow w_i + \Delta w_i \]
3.2. 更新量
\[ \Delta w_i = \eta (y_{\text{target}} – y_{\text{output}}) x_i \]
- \( w_i \) : 重み(更新前)
- \( \eta \) : 学習率(小さい正の値で、更新の大きさを調整するパラメータ)
- \( y_{\text{target}} \) : 目標の出力(正解ラベル)
- \( y_{\text{output}} \) : パーセプトロンの出力(予測値)
- \( x_i \) : 対応する入力値
4. 単純パーセプトロンの制約
単純パーセプトロンは基本的なモデルですが、いくつかの制約もあります。特に、データが線形分離可能な場合にしか正確な分類ができません。