更新:2025/02/21
【統計検定2級】試験直前!押さえておきたい最終確認重要ポイント総まとめ

本記事は統計検定2級の対策として,出題範囲である統計学の基礎知識や重要な概念を整理する目的でまとめたものです。ここでは,抽出法(多段抽出法・系統抽出法・層化抽出法・集落抽出法など)から始まり,続いてフィッシャーの3原則,時系列データの変動要因,ローレンツ曲線とジニ係数,確率分布の期待値と分散,そして分散分析や回帰分析(単回帰・重回帰)に関する内容を総合的に解説します。
目次
- 1. 抽出法
- 1.1. 多段抽出法
- 1.1.1. 二段抽出法
- 1.2. 系統抽出法
- 1.3. 層化抽出法
- 1.4. 集落(クラスター)抽出法
- 2. フィッシャーの3原則
- 3. 時系列データの変動要因
- 4. ローレンツ曲線とジニ係数
- 4.1. ローレンツ曲線
- 4.2. ジニ係数
- 5. 歪度と尖度
- 5.1. 歪度(Skewness)
- 5.2. 尖度(Kurtosis)
- 6. 確率分布の期待値と分散
- 6.1. 正規分布(Normal Distribution)
- 6.2. カイ二乗分布(Chi-square Distribution)
- 6.3. 一様分布(Uniform Distribution)
- 6.4. ベルヌーイ分布(Bernoulli Distribution)
- 6.5. 二項分布(Binomial Distribution)
- 6.6. ポアソン分布(Poisson Distribution)
- 6.7. 指数分布(Exponential Distribution)
- 6.8. 幾何分布(Geometric Distribution)
- 7. 分散分析(ANOVA)
- 7.1. 一元配置分散分析
- 8. 単回帰分析
- 9. 重回帰分析
- 9.1. 決定係数と自由度調整済み決定係数
- 9.2. 外挿(Extrapolation)
1. 抽出法
1.1. 多段抽出法
- 多段抽出法とは,サンプリングの段階を複数に分け,段階ごとに無作為抽出を行う方法です。
- 大規模な母集団を効率良く扱える反面,段階が増えるほど一度に集められるサンプル数が減ってしまう可能性もあるため,「三段抽出のほうが二段抽出より常に精度が高い」というわけではありません。
1.1.1. 二段抽出法
- 二段抽出法は,多段抽出法の中でも抽出を2回行う方法です。
- 大きな区画(例:県)を無作為に抽出
- 選ばれた県の中で細かい区画(例:市町村)を無作為に抽出
1.2. 系統抽出法
- 系統抽出法では,母集団の要素に番号を付し,最初の番号をランダムに決めたうえで,等間隔でサンプルを抽出します。
- 例: 母集団サイズ \( N \),抽出サンプルサイズ \( n \) とすると,等間隔 \( k \) を定め,乱数で決めた開始番号 \( r \) から \( r + k, r + 2k, \dots \) を抽出する手順です。
1.3. 層化抽出法
- 層化抽出法は,母集団をある基準で複数の層に分け,各層から無作為抽出を行う方法です。
- 母集団を層で区切ることで層内部が均質になるように設計すれば,推定の精度を高めやすい利点があります(年齢層別・地域別など)。
1.4. 集落(クラスター)抽出法
- 集落(クラスター)抽出法では,母集団をいくつかのグループに分割し,いくつかのグループを無作為に選び,選ばれたグループに所属する要素を全数調査します。
2. フィッシャーの3原則
実験計画法の礎を築いたロナルド・フィッシャーが提唱した,調査や実験を設計するうえで基本となる3原則です。
- 局所管理(Local Control)
- 可能な限りブロック(狭い範囲)を設定して条件を均質化し,ほかの要因の影響を除きやすくする。
- 無作為化(Randomization)
- サンプルの割り当てや処理をランダムに行い,系統的偏りを排除する。
- 繰り返し(Replication)
- 同じ処理を複数回行い,誤差を評価しやすくする。
3. 時系列データの変動要因
時系列データは,長期間にわたるデータを時系列に沿って観測したものです。その変動要因は以下の3つに分けられます。
- 傾向変動(Secular Trend)
- 長期的な上昇・下降などの大局的変動。
- 循環変動(Cyclical Variation)
- 3年~15年周期で周期的にくり返す変動。
- 季節変動(Seasonal Variation)
- 1年周期で周期的にくり返す変動。
- 不規則変動(Irregular Variation)
- 上記以外の偶然的な変動で,突発的要因などが含まれる。
4. ローレンツ曲線とジニ係数
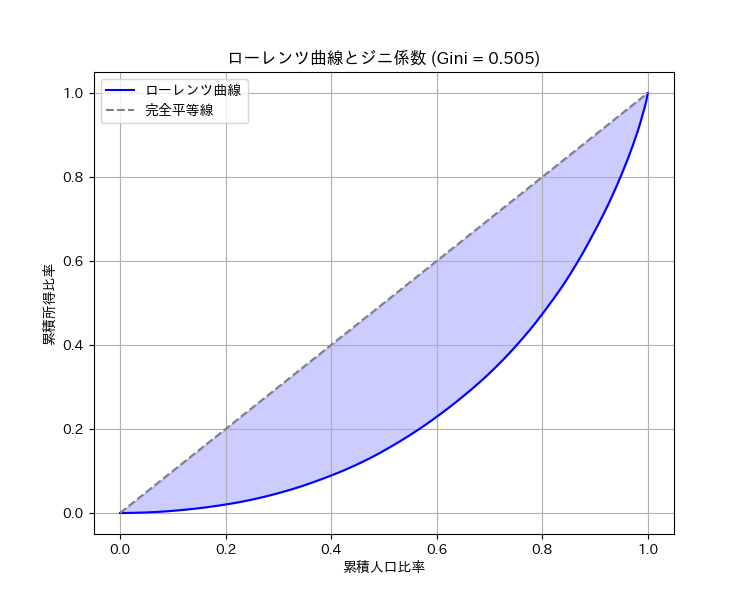
4.1. ローレンツ曲線
- 所得分布などの「不平等度合い」を可視化するための折れ線グラフ。
- 横軸に人口の累積相対度数,縦軸に累積所得比率を取ります。完全に平等な分布であれば45度線と一致し,不平等が大きいほど曲線は下方に湾曲します。
4.2. ジニ係数
- ジニ係数 \( G \) は,ローレンツ曲線と45度線(完全平等線)で囲まれた面積の2倍で定義され,\[ 0 \le G \le 1 \] の範囲をとります。
- 0 に近いほど平等,1 に近いほど不平等を表し,分布の偏りを評価する指標として広く使われます。
5. 歪度と尖度
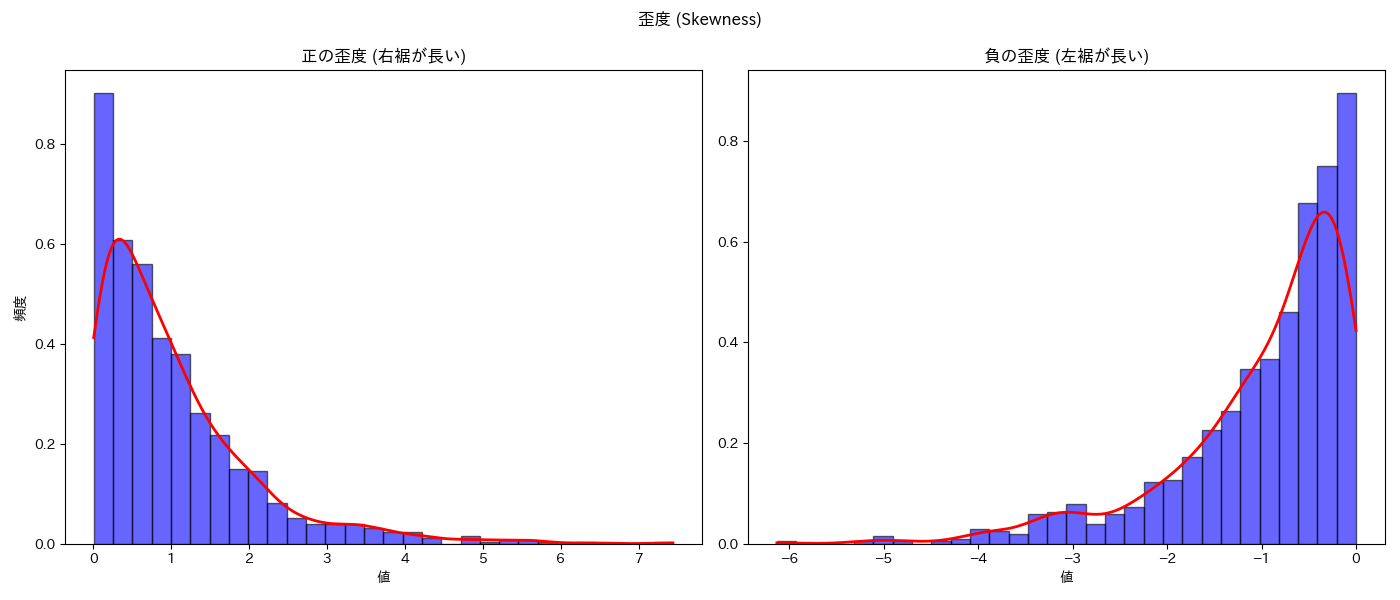
5.1. 歪度(Skewness)
- 歪度は、データの分布の非対称性を示す指標です。
- 正の歪度(右に歪んだ分布)は、右裾が長い。
- 負の歪度(左に歪んだ分布)は、左裾が長い。
- 指数分布は典型的に正の歪度を持ち、右方向に長い裾を持ちます。
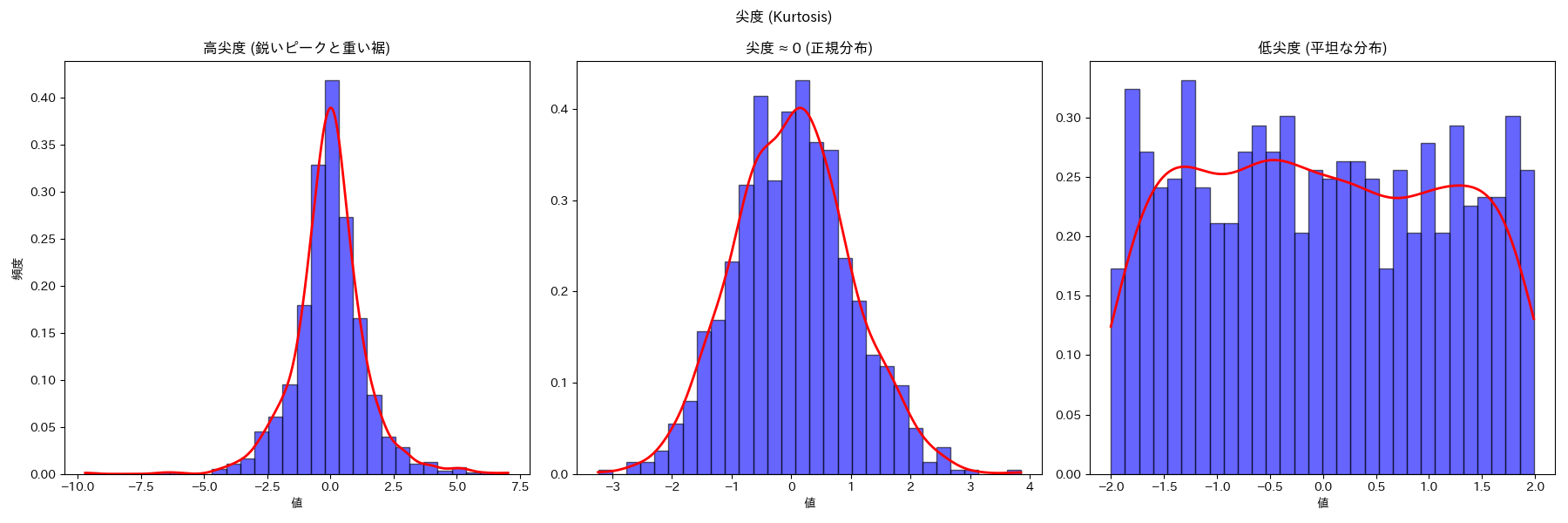
5.2. 尖度(Kurtosis)
- 尖度(せんど)は、データの分布の「とがり具合」や「裾野(すその)の広がり」を表す指標です。
- 尖度が正の値 → 分布の山が鋭くとがり、データが平均付近に集まりやすい。分布の裾が重い。
- 尖度が負の値 → 分布の山がなだらかで、データが平均から広く散らばる。分布の裾が軽い。
- 正規分布の尖度は 0 で、これを基準に「より尖った分布」か「より平らな分布」かを判断します。
6. 確率分布の期待値と分散
以下,代表的な分布の性質(期待値 \( E(X) \) と分散 \( \mathrm{Var}(X) \))をまとめます。
6.1. 正規分布(Normal Distribution)
正規分布の確率密度関数は
\[ f(x) = \frac{1}{\sqrt{2\pi}\,\sigma} \exp\!\Bigl(-\frac{(x-\mu)^2}{2\sigma^2}\Bigr), \quad -\infty < x < \infty. \]
- 期待値: \(\,E(X) = \mu\)
- 分散: \(\,\mathrm{Var}(X) = \sigma^2\)
6.2. カイ二乗分布(Chi-square Distribution)
- 自由度 \( k \) のカイ二乗分布の確率密度関数: \[ f(x) = \frac{1}{2^{k/2}\,\Gamma(k/2)}\, x^{k/2 – 1} e^{-x/2},\quad x>0. \]
- 期待値: \(\,E(X) = k\)
- 分散: \(\,\mathrm{Var}(X) = 2k\)
6.3. 一様分布(Uniform Distribution)
- 区間 \([a,b]\) 上の連続一様分布: \[ f(x) = \begin{cases} \frac{1}{b-a}, & a \le x \le b,\\ 0, & \text{それ以外}. \end{cases} \]
- 期待値: \(\,E(X) = \frac{a+b}{2}\)
- 分散: \(\,\mathrm{Var}(X) = \frac{(b-a)^2}{12}\)
6.4. ベルヌーイ分布(Bernoulli Distribution)
- 確率 \( p \) で成功(1),\(1-p\) で失敗(0) となる離散分布。
- 期待値: \(\,E(X) = p\)
- 分散: \(\,\mathrm{Var}(X) = p(1-p)\)
6.5. 二項分布(Binomial Distribution)
- 試行回数 \( n \),成功確率 \( p \) のもと,成功回数 \( k \) の分布。 \[ P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}. \]
- 期待値: \(\,E(X) = np\)
- 分散: \(\,\mathrm{Var}(X) = np(1-p)\)
6.6. ポアソン分布(Poisson Distribution)
- ポアソン分布はパラメータ \(\lambda\) の離散分布。事象の発生回数をモデル化する際に有用。
\[ P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!}. \] - 期待値: \(\,E(X) = \lambda\)
- 分散: \(\,\mathrm{Var}(X) = \lambda\)
6.7. 指数分布(Exponential Distribution)
- 指数分布は、事象がランダムに発生する間隔をモデル化する確率分布です。
- 確率密度関数(PDF)は次のように表されます。 \[ f(x) = \lambda e^{-\lambda x}, \quad x > 0, \quad \lambda > 0 \]
- 期待値: \(\,E(X) = \frac{1}{\lambda}\)
- 分散: \(\,\mathrm{Var}(X) = \frac{1}{\lambda^2}\)
6.8. 幾何分布(Geometric Distribution)
- 幾何分布はパラメータ \( p \)(成功確率)で,初めて成功が出るまでの試行回数を表す分布(定義のバリエーションあり)。 \[ P(X = k) = (1-p)^{k-1} p,\quad k=1,2,3,\dots \]
- 期待値: \(\,E(X) = \frac{1}{p}\)
- 分散: \(\,\mathrm{Var}(X) = \frac{1-p}{p^2}\)
7. 分散分析(ANOVA)
- 分散分析は,3群以上(2群でも可)の母平均に差があるかを一度に検定する手法です。
- データに影響を与えるものを要因,要因が取りうる具体的条件を水準と呼びます。
7.1. 一元配置分散分析
- 要因が1つだけある分散分析が一元配置分散分析です。
- 群間のばらつきを示す「水準間平方和(SS between)」と,群内のばらつきを示す「残差平方和(SS error)」の比(F値)を使い,母平均の差を検定します。
- 水準間平均平方: 水準間平方和 ÷ 自由度(\(a – 1\))
- 残差平均平方: 残差平方和 ÷ 自由度(\(N – a\))
- F値: (水準間平均平方) ÷ (残差平均平方)
8. 単回帰分析
- 説明変数が1つの場合の線形回帰モデルです。
- 残差平方和(SSE)を最小にするように回帰係数(切片,傾き)を推定します。
- 残差平方和を自由度 \( n – 2 \) で割ったものが,誤差項の分散の不偏推定量となります。
9. 重回帰分析
- 説明変数が2つ以上ある線形回帰モデルです。
- ダミー変数は質的データを0/1で表したものを説明変数として用いる方法です。(機械学習でいうOne-Hotエンコーディング)
- 多重共線性(Multicollinearity)
- 説明変数どうしの相関が高いと,係数推定が不安定になる問題です。
- 個別には有意に見えても,他の説明変数と強く相関している場合はモデルに入れることを慎重に検討する必要があります。
9.1. 決定係数と自由度調整済み決定係数
- 決定係数 \( R^2 \): モデルの当てはまりの良さ(0~1)。値が大きいほど目的変数をよく説明していることを示唆します。単回帰分析の場合は、相関係数の2乗に等しい。
- 自由度調整済み決定係数(Adjusted \( R^2 \)): 説明変数を増やした場合のペナルティを考慮した修正指標。
- 特にモデル選択の際に「過剰な説明変数の追加による過適合」を防ぐ目的で重視されます。
9.2. 外挿(Extrapolation)
- モデルを,データが得られた範囲を超えて予測に用いることです。
統計検定2級の学習者に朗報! 「統計検定2級 公式問題集[CBT対応版](実務教育出版)」 が発売されました! 🎉
本書は 分野ごとにCBT形式の問題を並べ、さらに模擬テストを収録 した充実の内容。 実際の試験を意識した構成 で、効率よく対策ができます。

PR




