【デコーディング手法】top_p(nuclear sampling)の意味と使い方について



1. top_p
近年、自然言語処理の分野で大規模な言語モデルが注目を集めています。これらのモデルはテキスト生成や対話システムなど、多岐にわたる応用が可能です。その中で、モデルが生成するテキストの質を左右する重要な要素として「サンプリング手法」があります。今回は、その中でも「nuclear sampling」と呼ばれる手法と、そのハイパーパラメータである「top_p」について詳しく解説します。
2. top_pサンプリングとは
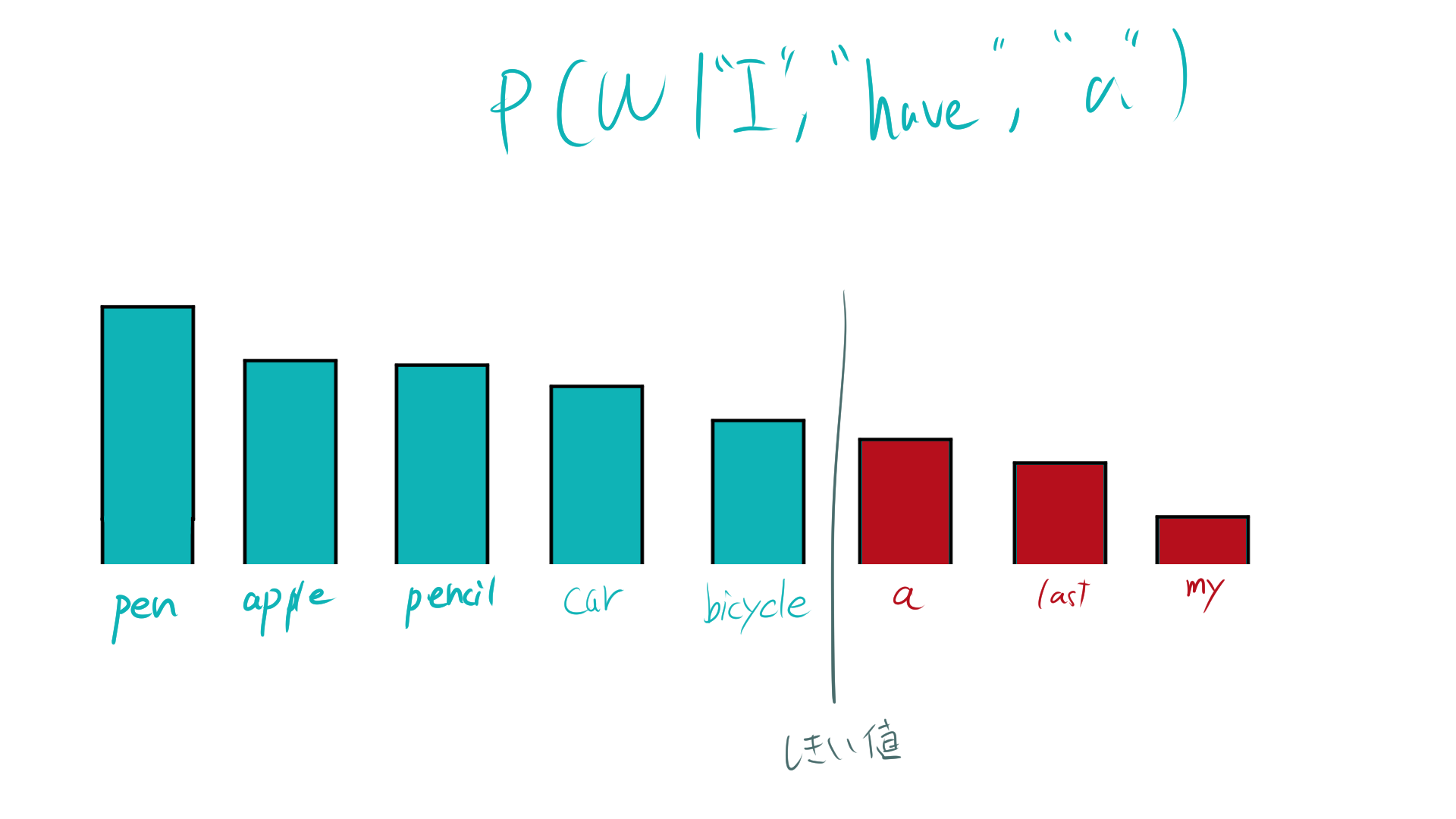
「nuclear sampling」は、top_pサンプリングとも呼ばれ、確率分布(ソフトマックス関数の出力)の上位の単語から累積確率が特定の閾値(top_p)を超えるまでの単語を候補とし、その中からランダムに単語を選択する手法です。
- モデルが予測する全ての単語の確率を降順に並べる。
- 上位の単語から順に累積確率を計算し、累積確率がtop_pを超えるまでの単語を選択肢とする。
- 選択肢の中からランダムに次の単語をサンプリングする。
2.1. top_pの役割と効果
top_pは0から1までの値を取り、累積確率の閾値を決定します。
- 小さいtop_p(例:0.1):上位のごく一部の単語を考慮するため、生成されるテキストは一貫性が高くなりますが、多様性が低くなります。
- 大きいtop_p(例:0.9):より多くの単語を考慮するため、多様性が高まりますが、一貫性が低下する可能性があります。
3. Transformersにおける利用方法
Transformersライブラリでtop_p(または nucleus sampling)を使用することで、生成されるテキストの多様性を制御できます。この方法は、トークンの確率分布のうち、累積確率がtop_p(例: 0.9)以下になるトークンの集合から次のトークンを選択します。
以下に、Transformersでtop_pを設定してテキストを生成する具体的な例を示します。
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルとトークナイザーのロード
model_name = "gpt2" # 適切なモデル名を指定
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 入力テキスト
input_text = "Once upon a time in a faraway land"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# 生成設定
output = model.generate(
input_ids,
do_sample=True, # サンプリングを有効化
top_p=0.9, # nucleus sampling(累積確率の閾値)
max_new_tokens=50
)
# 結果のデコードと表示
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)model.generateでサンプリングを指定することができます。
3.1. top_p=0.1の時の出力
Once upon a time in a faraway land, the sun was shining, and the moon was shining. The sun was shining, and the moon was shining. The sun was shining, and the moon was shining. The sun was shining, and the moon was shining. The sun was shining,
テキストは「太陽が輝き、月が輝いている」というフレーズを何度も繰り返しています。
3.2. top_p=0.9の時の出力
Once upon a time in a faraway land, where the earth lies in a state of perpetual motion, there are those who believe that we are here in the dream, which is eternal, which is beyond all comprehension. In order to get closer to this truth and to understand what the future is
4. 数式で表す
語彙の集合を \( V \)、言語モデルに与えられたプロンプトを \( x \) とします。各単語 \( w \in V \) に対して、プロンプトが与えらたときの単語の確率、つまり条件付き確率 \( P(w|x) \) を計算します。\( P(w|x) \) に基づいて、語彙 \( V \) 内の単語を降順に並べます。
\[ P(w_1|x) \geq P(w_2|x) \geq P(w_3|x) \geq \dotsb \geq P(w_N|x) \]
累積確率を計算し、累積確率が閾値 \( p \) を初めて超える最小のインデックス \( k \) を見つけます。
\[ \sum_{i=1}^{k} P(w_i|x) \geq p \]
ここで、集合 \( S_p \) を以下のように定義します。
\[ S_p = \{ w_1, w_2, \dotsc, w_k \} \subseteq V \]
集合 \( S_p \) 内の各単語の確率を正規化します。$Z=|S_p|$とすると、
\[ P'(w_i|x) = \frac{P(w_i|x)}{Z} \quad \text{ただし} \quad Z = \sum_{j=1}^{k} P(w_j|x) \]
正規化された確率 \( P'(w_i|x) \) に基づいて、集合 \( S_p \) から次の単語をサンプリングします。
5. top_pに関連する論文
The Curious Case of Neural Text Degeneration



