【Transformers】温度(temperature)の意味とは?ソフトマックス関数の調整について



1. temperature
Transformersのtemperatureは、文章の生成タスクにおいて、モデルが生成する単語(トークン)の確率分布を調整するために使われるハイパーパラメータです。
2. 確率分布とsoftmax関数
まず、言語モデルでは通常、次に出力するトークンの確率分布をsoftmax関数を使って計算します。softmaxは、ロジットを入力として、それを確率として解釈できる分布に変換する関数です。この分布に基づいて、次に生成されるトークンが選ばれます。softmaxは次のようになります。
\[ P(x_i) = \frac{e^{z_i}}{\sum_{j} e^{z_j}} \]
ここで、\( z_i \)はトークン\( i \)のロジットです。
2.1. temperatureによる調整
\[ P(x_i) = \dfrac{e^{\dfrac{z_i}{T}}}{\sum_{j} e^{\dfrac{z_j}{T}}} \]
ここで、\( T \)がtemperatureです。\( T \)がこのように分母にあるため、temperatureの値を変えると、次のような影響が生じます。
- \( T > 1 \)(高いtemperature):各トークン間の差が縮まります。これにより確率分布が平坦になり、もともと確率が低かったトークンも選ばれる可能性が高くなります。このため、生成がランダム性を帯び、多様な結果が得られます。
- \( T < 1 \)(低いtemperature):確率の高いトークンがさらに強調されます。結果として、もともと確率が高いトークンが選ばれる可能性が高まり、分布がシャープになります。これにより、生成がより決定的(同じ入力で同じ出力が得られやすくなる)になります。
3. なぜこのようになるのか
このように動作する理由は、temperatureが確率分布をスケール(伸縮)させることによります。高いtemperatureでは分布が平坦になり、低いtemperatureでは分布がシャープになります。この調整により、モデルの生成が多様性を持つか、より決定的になるかが変わるのです。
3.1. 直感的な理解
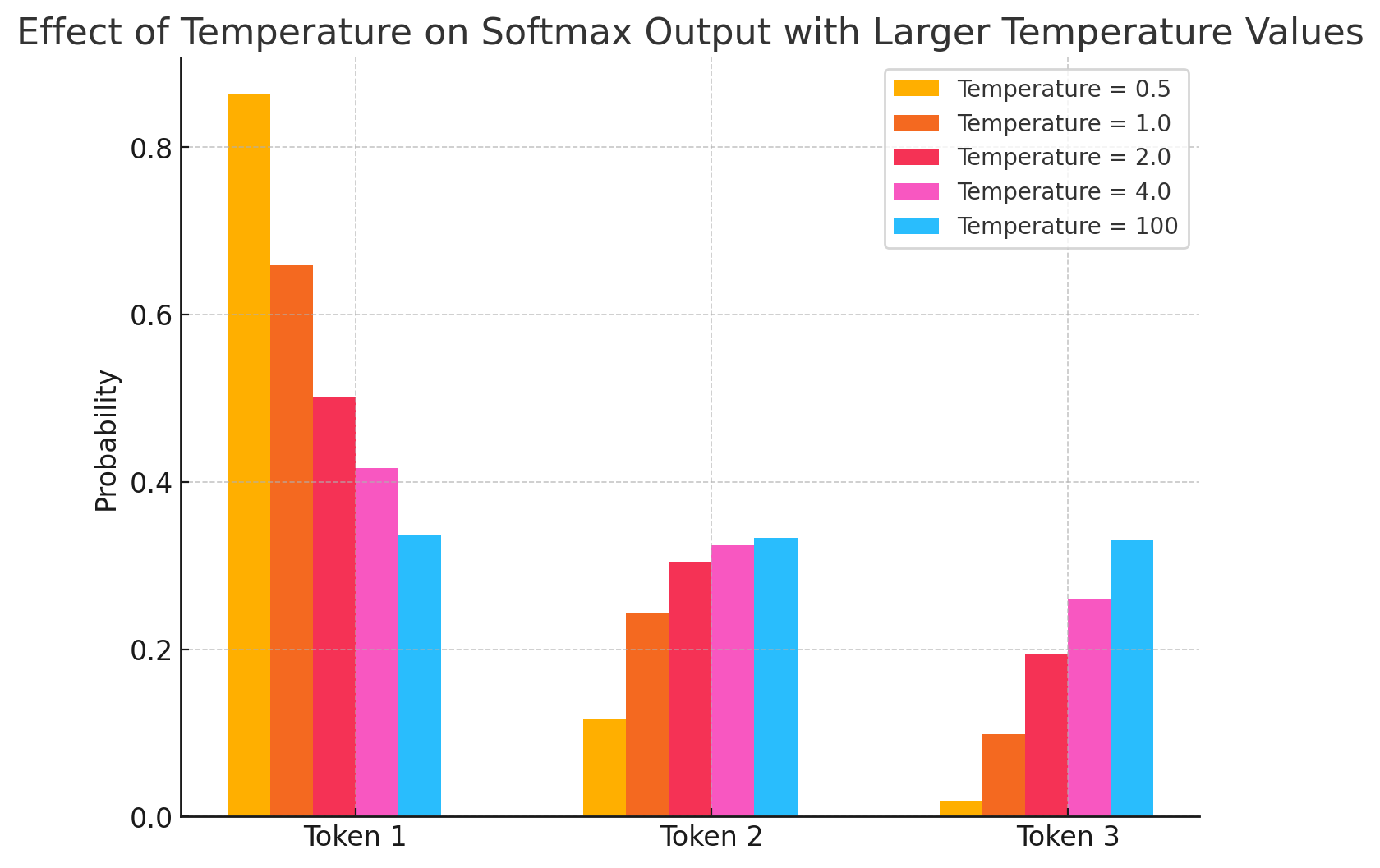
- Temperature = 0.5: 分布がシャープになり、最も高いロジット(Token 1)の確率が強調されています。
- Temperature = 1.0: 通常のsoftmaxであり、各トークンの確率がロジットに基づいて計算されています。
- Temperature = 2.0: 確率分布が平坦になり、Token 1の確率が下がり、他のトークンの確率が上がっています。
- Temperature = 4.0: 確率分布がさらに平坦になり、全てのトークンがほぼ同等の確率で選ばれる状態になっています。これは、非常にランダムな生成結果を生むことを意味します。
- Temperature = 100: 確率分布が極端に平坦になり、すべてのトークンがほぼ同じ確率で選ばれるようになっています。極端に大きなtemperatureを設定すると、元のロジットの影響がほぼ消え、完全にランダムな選択に近い状態になります。
4. 使い方
言語モデルでは、temperatureの設定によって生成される文章の多様性が大きく変わります。低いtemperatureでは確率が高い単語が選ばれやすく、予測された文章がより安定しやすい一方、高いtemperatureではよりランダムで予測不可能な文章が生成されやすくなります。
ここでは、論理回路の「inverter」に関して、temperatureを変化させた場合にどのような応答が得られるか見てみましょう。
4.1. Python
以下のコードでは、Meta-Llama-3-8Bモデルを使用して「inverterとは何か?」という質問に対する応答を生成します。AutoModelForCausalLMのgenerateのパラーメータでtemperatureを指定することができます。
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import set_seed
import torch
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B"
,device_map="auto"
,load_in_4bit=True)
set_seed(42)
text = "Do you know inverter?\n"
input_ids = tokenizer.encode(text, return_tensors='pt')
generated_token = model.generate(input_ids,max_new_tokens=100,temperature=1.0)
out = tokenizer.decode(generated_token[0], skip_special_tokens=True)4.2. temperature=1.0のとき
訳:私は、インバータという言葉が通信の世界では新しい言葉だと思います。長年、私はインバータの販売や保守に携わってきたため、インバータに非常に詳しいです。インバータは私たちの社会では一般的な言葉ですが、一般の消費者はインバータの概念には馴染みがあるものの、インバータ自体にはあまり馴染みがないのではないかと思います。インバータは「インバート」とも呼ばれています。
論理回路のインバーターではなく、なんのインバーターの話をしているのかわからない文章が生成されました。
4.3. temperature=1.8のとき
私は、ほとんどの人がインバータの基本的な概念を聞いたことがあると思います。しかし、一般的な場合、インバータは正弦波の電圧を生成します(アメリカでは60Hz、イギリス、日本、ヨーロッパでは50Hzの周波数)。この生成された正弦波の電流は、コンピュータや正弦波電流で動作する必要がある産業用機器に多くの悪影響を与える可能性があります。そのため、もし家庭にコンピュータがなく(周辺機器だけがある場合)、インバータは必要ありません。
4.4. temperature=20.0のとき
Subject Do, Sep13.23[Sun]-200:2/5-:00—H=2D8/22/03B03—-GMT1:
From Internet provider User Id IP info;—No
What I know are only invertar types–so as, DC->5–>12.1V(0f)–12.VAC; in 90s DC is >21—-3.
かなり破綻した、文章が生成されました。
4.5. temperature=0.001のとき
「インバータは、直流電力を交流電力に変換する装置です。」ということを繰り返し言っています。非常に低いtemperatureの場合、最も確率の高い単語が繰り返し選ばれるため、同じ文章が繰り返されてしまいます。このように、予測が極端に安定してしまい、バリエーションが失われます。
4.6. temperature=0.01のとき
temperature =0.001のときと同じ文章が生成されました。このことからも、temperatureが低い場合にはもともと確率が高いトークンが選ばれる可能性が高くなることがわかります。
4.7. まとめ
このことからも、temperatureは高すぎても、低すぎてもいいわけではにことがわかります。言語モデルにあった、temperatureを指定することでテキストの生成の品質を向上させることができます。




