更新:2024/09/08
NLTKとWordNetの基本的な使い方・類義語について


ふゅか
ねえ、NLTKって知ってる?WordNetっていう辞書データベースにアクセスできるんだって!超便利だよね♪

はるか
ああ、知ってる。単語の意味や同義語、反意語が簡単にわかる。
目次
1. NLTKとWordNet
NLTK (Natural Language Toolkit) は、WordNet という辞書データベース(シソーラス)にアクセスするための便利なインターフェースを提供しています。これにより、単語の意味、同義語、反意語などを簡単に調べることができます。以下に、NLTK で WordNet を使う基本的な方法を説明します。
2. インストール・準備
まず、NLTK がインストールされていることを確認してください。pip を使ってインストールできます。
pip install nltk
次に、WordNet のデータをダウンロードする必要があります。
import nltk
nltk.download('wordnet')
nltk.download('omw-1.4') # オプション: 多言語対応の WordNet データ
3. 基本的な使い方
3.1. Synset(同義語セット)
Synset は、共通の意味を持つ同義語の集合です。ある単語の Synset を取得するには、次のようにします。
from nltk.corpus import wordnet as wn
# "dog" の Synset を取得
synsets = wn.synsets('dog')
print(synsets) WordNetに様々な同義語が登録され、文字通りの「犬」以外にも、複数の異なる意味が関連しています。
WordNetに様々な同義語が登録され、文字通りの「犬」以外にも、複数の異なる意味が関連しています。
はるか
Synsetは英語で一つ以上の同義語のこと。
3.2. 定義と例文
Synset を取得したら、その定義や例文にアクセスできます。例文は、空になる場合があります。
# "letter" の最初の Synset を取得
letter = wn.synsets('letter')[0]
# 定義を取得
print(letter.definition())
# 例文を取得
print(letter.examples())
3.3. Lemma(同義語)
Synset の同義語(Lemma)を取得することができます。
a = wn.synsets('a')[2]
# "a" の Synset の Lemma を取得
lemmas = py.lemmas()
print([lemma.name() for lemma in lemmas])
デオキシアデノシン一リン酸とAがaの同義語になっていることがわかります。
ふゅか
あとは、Synsetから同義語、つまりLemmaも取り出せるのよ!
はるか
そうだね。同義語のリストを作りたいときに役立つ。
3.4. 反意語
反意語を見つけるには、Lemma を調べて、その反意語を取得します。
# "good" の反意語を見つける
good = wn.synsets('good')[1]
antonyms = [lemma.antonyms() for lemma in good.lemmas() if lemma.antonyms()]
print(antonyms)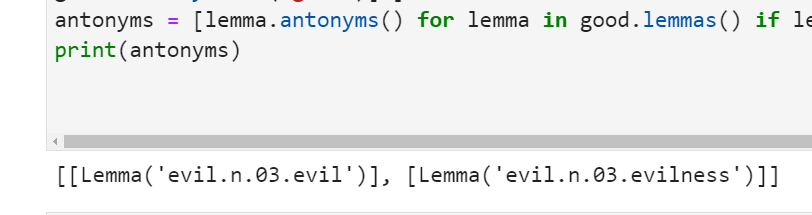
3.5. Hypernym(上位語)と Hyponym(下位語)
単語の上位語や下位語を取得することができます。
token = wn.synsets('token')[0]
# "token" の最初の Synset の Hypernym を取得
hypernyms = token.hypernyms()
print(hypernyms)
# "token" の最初の Synset の Hyponym を取得
hyponyms = token.hyponyms()
print(hyponyms)
ふゅか
HypernymとHyponymも便利だよ!Hypernymはもっと一般的な用語、Hyponymは具体的な用語って感じ。これで単語の階層関係が見えてくる!
3.6. パス類似度の計算
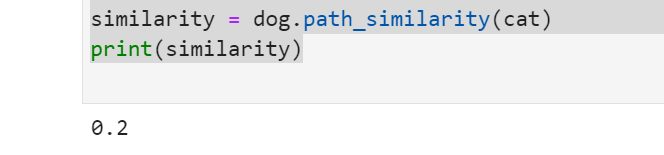
Synset 間の類似度をパス類似度で測定することもできます。
# "dog" と "cat" の Synset を取得
dog = wn.synsets('dog')[0]
cat = wn.synsets('cat')[0]
# パス類似度を計算
similarity = dog.path_similarity(cat)
print(similarity)
PR




